当一个新的数据块准备好时,_transform方法被调用 。它以Buffer对象的形式被接收,并被转换为字符串,被最小化,并使用push()方法输出 。一旦数据块处理完成,一个callback()函数就会被调用 。
应用程序启动了文件读写流,并实例化了一个新的compress对象:
// process streamconstreadStream = createReadStream(input),wr// process streamconstreadStream = createReadStream(input),writeStream = createWriteStream(output),compress = new Compress();console.log(`processing ${ input }`)传入的文件读取流定义了.pipe()方法,这些方法通过一系列可能(或可能不)改变内容的函数将传入的数据输入 。在输出到可写文件之前,数据通过compress转换进行管道输送 。一旦流结束,最终on('finish')事件处理函数就会执行:
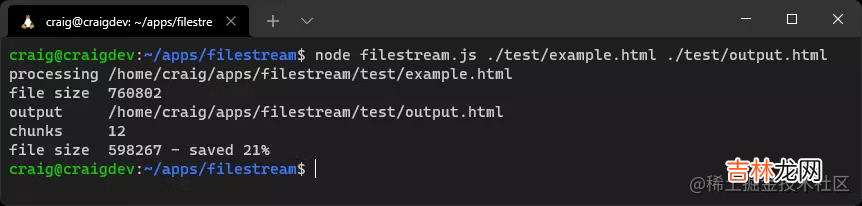
readStream.pipe(compress).pipe(writeStream).on('finish', () => {console.log(`file size${ compress.lengthOrig }`);console.log(`output${ output }`);console.log(`chunksreadStream.pipe(compress).pipe(writeStream).on('finish', () => {console.log(`file size${ compress.lengthOrig }`);console.log(`output${ output }`);console.log(`chunks${ compress.chunks }`);console.log(`file size${ compress.lengthNew } - saved ${ Math.round((compress.lengthOrig - compress.lengthNew) / compress.lengthOrig * 100) }%`);});使用任意大小的HTML文件的例子运行项目代码:
node filestream.js ./test/example.html ./test/output.html
文章插图
这是对Node.js流的一个小例子 。流处理是一个复杂的话题,你可能不经常使用它们 。在某些情况下,像Express这样的模块在引擎盖下使用流,但对你的复杂性进行了抽象 。
你还应该注意到数据分块的挑战 。一个块可以是任何大小,并以不便的方式分割传入的数据 。考虑对这段代码最小化:
<script type="module">// example scriptconsole.log('loaded');</script>两个数据块可以依次到达:<script type="module">// example以及:<script>console.log('loaded');</script>独立处理每个块的结果是以下无效的最小化脚本:<script type="module">script console.log('loaded');</script>解决办法是预先解析每个块,并将其分割成可以处理的整个部分 。在某些情况下,块(或块的一部分)将被添加到下一个块的开始 。尽管会出现额外的复杂情况,但是最好将最小化应用于整行 。因为
<!-- -->和/* */注释可以跨越不止一行 。下面是每个传入块的可能算法:- 将先前块中保存的任何数据追加到新块的开头 。
- 从数据块中移除任意整个
<!--到-->以及/*到*/部分 。 - 将剩余块分为两部分 。其中
part2以发现的第一个<!--或/*开始 。如果两者都存在,则从part2中删除除该符号以外的其他内容 。如果两者都没有找到,则在最后一个回车符处进行分割 。如果没有找到,将part1设为空字符串,part2设为整个块 。如果part2变得非常大--也许超过100,000个字符,因为没有回车符--将part2追加到part1,并将part2设为空字符串 。这将确保被保存的部分不会无限地增长 。 - 缩小和输出
part1。 - 保存
part2(它被添加到下一个块的开始) 。
经验总结扩展阅读














- 飞机上可以带辣椒酱吗
- 经济价值高的树种有哪些 世界十大经济树木排名榜
- 可乐鸡翅没有料酒可以用什么代替
- 芒果皮有毒吗
- 原神没有课题的答案任务是什么
- 冰箱里一定有李斯特菌吗
- 学蛋糕甜点适合在哪里学
- 3.5l的砂锅有多大
- 冻干免煮银耳羹还有营养吗?
- 红葱头的吃法