重点:套接字本质上也是一个文件描述符,指向的是一个“网络文件” 。普通文件的文件缓冲区对应的是磁盘,数据先写入文件缓冲区,再刷新到磁盘,“网络文件”的文件缓冲区对应的是网卡,它会把文件缓冲区的数据刷新到网卡,然后发送到网络中 。创建一个套接字做的工作就是打开一个文件,接下来就是要将该文件和网络关联起来,这就是绑定的操作,完成了绑定,文件缓冲区的数据才知道往哪刷新 。
网络字节序我们已经知道,内存中的多字节数据相对于内存地址有着大端和小端的区分 。同样,网络数据流同样有大端和小端的区分 。
思考一下,如何定义网络数据流的地址呢?
发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出,接收主机把从网络上接到的字节一次保存在接收缓冲区中,也就是按照内存地址从低到高的顺序保存 。
网络数据流的地址应该这样规定:先发出的数据是低地址,后发出的数据是高地址 。
- 大端字节序: 高位存放在低地址,低位存放在高地址
- 小端字节序: 低位存放在低地址,高位存放在高地址

文章插图
如果双方主机的数据在内存存储的字节序不同,就会造成接收方收到的数据出现偏差,所以为了解决这个问题,又有了下面的规定:
- TCP/IP协议规定,网络数据流采用
大端字节序,不管这台主机是大端机还是小端机, 都会按照这个TCP/IP规定的网络字节序来发送/接收数据 - 所以如果发送的主机是小端机,就需要把要发送的数据先转为大端,再进行发送,如果是大端,就可以直接进行发送 。
#include <arpa/inet.h>uint32_t htonl(uint32_t hostlong);uint16_t htons(uint16_t hostshort);uint32_t ntohl(uint32_t netlong);uint16_t ntohs(uint16_t netshort);说明:- h代表的是host,n代表的是network,s代表的是16位的短整型,l代表的是32位长整形
- 如果主机是小端字节序,函数会对参数进行处理,进行大小端转换
- 如果主机是大端字节序,函数不会对这些参数处理,直接返回
Socket常见的API常用的有以下几个,后面会具体的介绍
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)int socket(int domain, int type, int protocol);// 绑定端口号 (TCP/UDP, 服务器)int bind(int socket, const struct sockaddr *address,socklen_t address_len);// 开始监听socket (TCP, 服务器)int listen(int socket, int backlog);// 接收请求 (TCP, 服务器)int accept(int socket, struct sockaddr* address,socklen_t* address_len);// 建立连接 (TCP, 客户端)int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen);Sockaddr结构体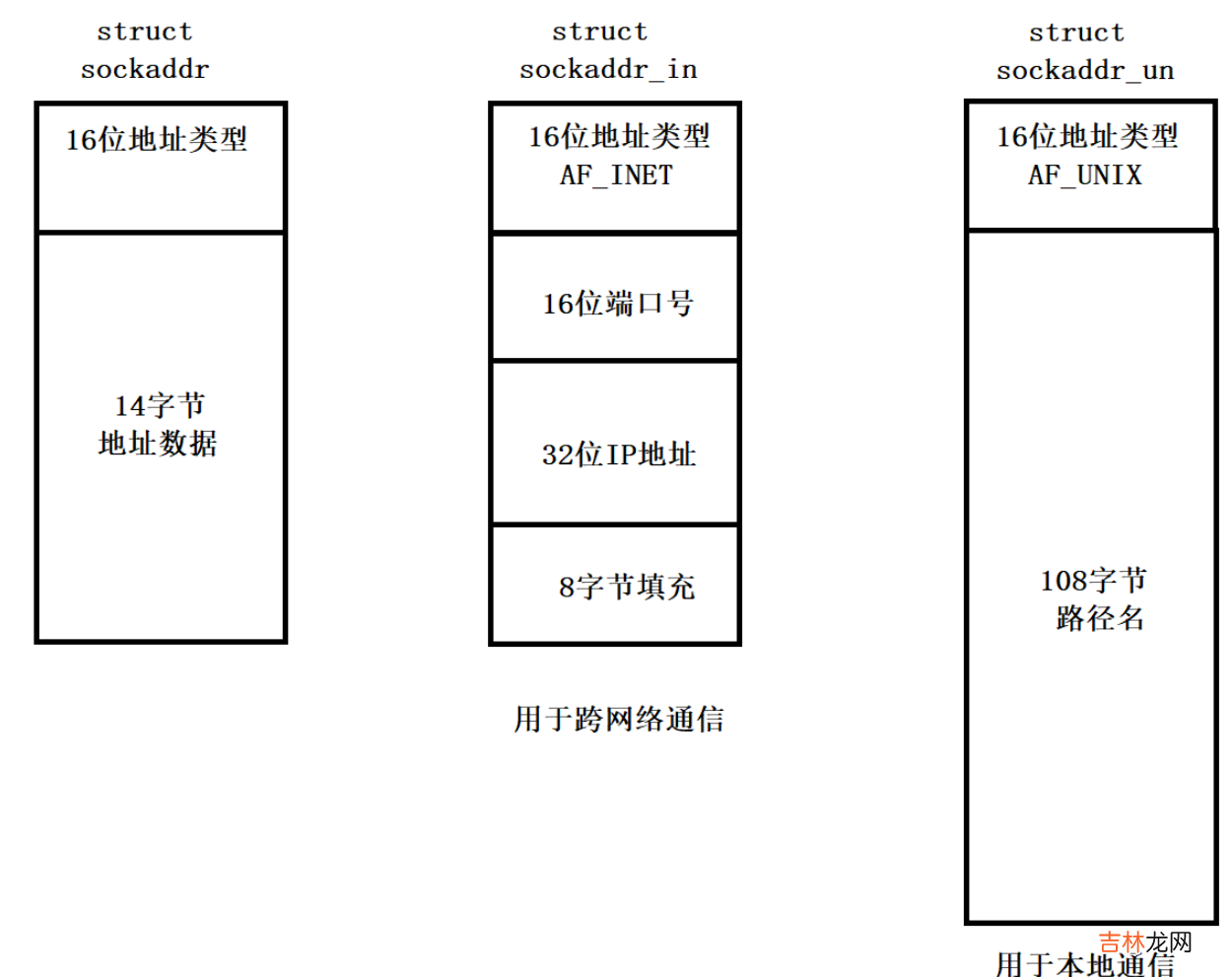
文章插图
- sockaddr_in用来进行网络通信,sockaddr_un结构体用来进行本地通信
- sockaddr_in结构体存储了协议家族,端口号,IP等信息,网络通信时可以通过这个结构体把自己的信息发送给对方,也可以通过这个结构体获取远端的这些信息
- 可以看出,这三个结构体的前16位时一样的,代表的是协议家族,可以根据这个参数判断需要进行哪种通信(本地和跨网络)
经验总结扩展阅读
- 抓包分析 TCP 握手和挥手
- 概念+协议的了解+OSI七层模型,TCP/IP五层协议,网络数据传输流程 Linux--网络基础
- 关于网页实现串口或者TCP通讯的说明
- 如何kill一条TCP连接?
- TCP 序列号和确认号是如何变化的?
- 2d游戏怎么编程(怎么编写一个2d游戏)
- 怎么编写游戏程序(游戏外挂编写教程)
- Tomcat 调优之从 Linux 内核源码层面看 Tcp backlog
- 手写编程语言-如何为 GScript 编写标准库
- 编写HelloWorld并运行








