手机上的输入文字的功能,用过的一个非常好用的语音识别输入文字的软件 。
操作的方法可以按照下面的步骤方法来进行转换 , 简单好用,轻松就能够完成需要的文字输入哦 。
【语音识别的技术原理是什么】
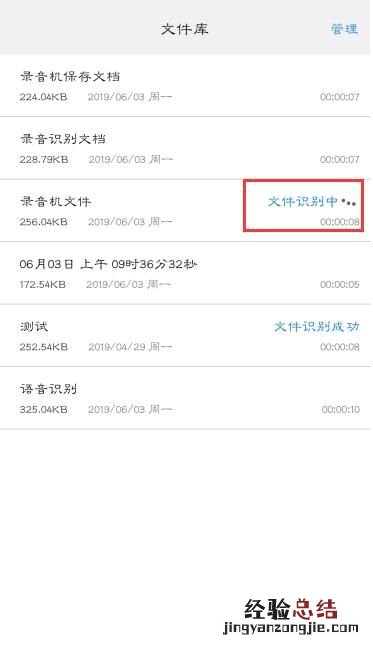
1)在应用市场找到这个工具将它安装在手机之后在语音识别的页面中选择:录音机,就可以录制音频了;

2)等待录制结束 , 这里我们需要将音频文件保存一份,然后进入手机文件库的页面,找到录制的音频;

3)点击右上角的转文字字样,就可以将录制好的音频文件转换成文字了;
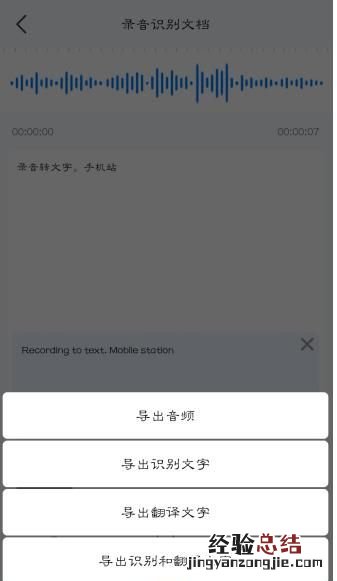
4)最后 , 我们同样可以进入文字页面,进行翻译、复制、导出等操作 。
怎么将录音转成文字?在线语音转文字、手机音频转文字看这里
看图
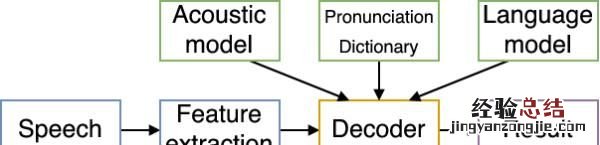
- 编码:把语音变成向量
- 频域信息:人类是通过振动频率来判断声音的,所以要用傅里叶变换来完成时域频域之间的转换;
- 特征:如,MFCC是依照人耳的听声特点提出的filter 。然后我们有了语音向量 。
- 训练:从数据中学习对语音的判断,而不是用人工的规则 。
- 声学模型(acoustic model):用于识别语音向量;可用GMM或DNN等方法来识别向量,用DTW或HMM或CTC来对齐(alignment)识别结果的输出(单词从何时开始,何时结束)
- 字典(dictionary):多数模型并不是以单词,而是以音素为识别单位 。当识别出? p l这三个音素时,利用字典,就可以判断出所说的词是apple 。
- 语言模型(language model):我们在听老外说错误的中文时依然能够识别内容是因为我们有关于语法的知识,可以调整声学模型所识别出的不合逻辑的词语 。这就是语言模型的作用
- 解码:用训练好的模型组合起来就可以通过判断新的语音向量,来识别语音了 。















