broker在kafka的服务端运行 , 一台服务器相当于一个broker;每个broker下可以有多个topic , 每个topic可以有多个partition , 在producer端可以对消息进行分区 , 每个partiton可以有多个副本 , 可以使得数据不丢失 。
通常以集群模式 , 下面来阐述一下broker的几个状况 。
分区数据与副本kafka的partition有一个leader的数据区域 , 是为了接收producer端发送的数据;也可以通过克隆leader的方式创建副本 , leader与副本保持数据同步 , 也就是为了在极端情况下的数据备份 , 每个分区的副本交错的存在于其它分区中 , 尽量以平均方式存放于各分区中 , 也可以手动指定存放的分区(假设是因服务器硬件的配置不同) , 当极端情况下 , leader宕机后 , 自动启用副本作为新leader角色 , 负责接收消息 。
leader与副本保持通信 , 副本持续向leader发送健康请求 , 超过30秒无连接的副本 , 从关联的副本中删除关系;副本数据默认为1个 , 通常我们至少设置为2个 。
# 副本数量配置项(默认为1)mis.insync.replicasbroker的应答机制在上一章阐述过 , broker是对producer的应答 , 它会告诉producer , 对接收到的数据处理情况;应答等级:(配置项为 acks)
- 0:不用等落地磁盘 , 直接应答
- 1:leader落地磁盘后应答
- all:leader和副本都落地磁盘后再应答(默认)
- broker单次启动运行 , 会有一个唯一的运行编号
- 每个分区都会有一个唯一的分区编号
- producer发送的每条消息都会有一个唯一的消息编号
# 幂等性(默认开启)enable.idempotence=true数据防丢失通过以上内容的了解 , 为防止数据的丢失 , 这里可以这样做:1、应答机制设为-1 , 确保leader和副本都保存完成2、分区副本至少有两个 , 确保随时有可启用的副本数据当做到 数据不重复 + 数据防丢失 , 体现出数据的完整性、安全性、一致性 。
数据的按序broker中的leader在接收数据时 , 分区缓存按序最多可存5个请求数据 , 成功的消息请求会落地 , 消息请求按序落地磁盘 , 若一次消息请求失败 , producer会尝试重发 , 此时leader分区的数据落地动作会暂停 , 但会缓存新收到的请求数据 , 积满5个后暂停接收 , 直至之前失败的消息请求成功后 , 再从此消息处 , 重新开始按序落地磁盘 。多分区按发送序号落地磁盘 。
leader分区缓存接收消息示意图
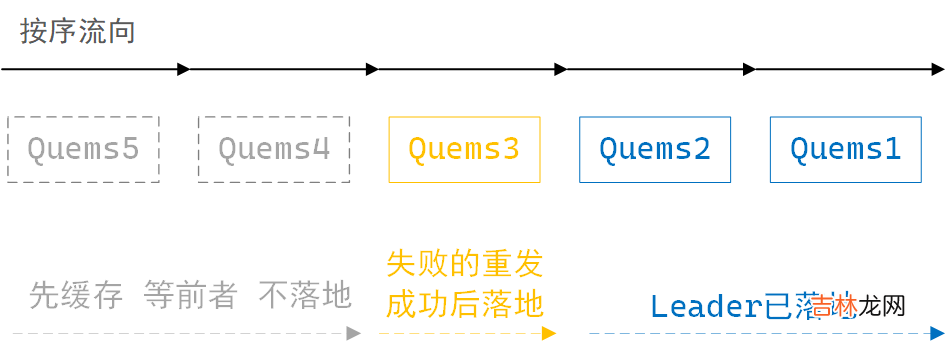
文章插图
这里认为:开启幂等性 + 接收积压个数 + 按序落地磁盘 , 可以确保单个topic多分区消息不乱序 。
leader partition 的自动平衡假如 , 个别broker中的分区过多 , 个别broker中的分区过少 , 这不符合负载均衡 。kafka默认开启了每间隔一段时间 , 自动检测分区分布的差异值是否超过了警戒值 , 当超过设定的警戒值时 , 自动触发平均分布的动作 。
# 开启自动平衡分布(默认)auto.leader.rebalance.enable=true# 不平衡警戒触发值(默认1%)leader.imbalance.per.broker.percentage# 检测间隔时间(默认300秒)leader.imbalance.check.interval.seconds=300
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- Mobile 我的Vue之旅、05 导航栏、登录、注册
- 父亲节素材
- 我的伯父鲁迅先生中的四个小标题
- Docker搭建kafka及监控
- 我的 Kafka 旅程 - Consumer
- 电视剧我的莫格利男孩一共多少集?
- 我的莫格利男孩高婕结局是什么?
- 我的邻居睡不着宋米哆身世是什么?
- 电视剧我的体育老师结局怎样?
- 我的莫格利男孩储时和谁在一起?
















