SSB Query
文章插图
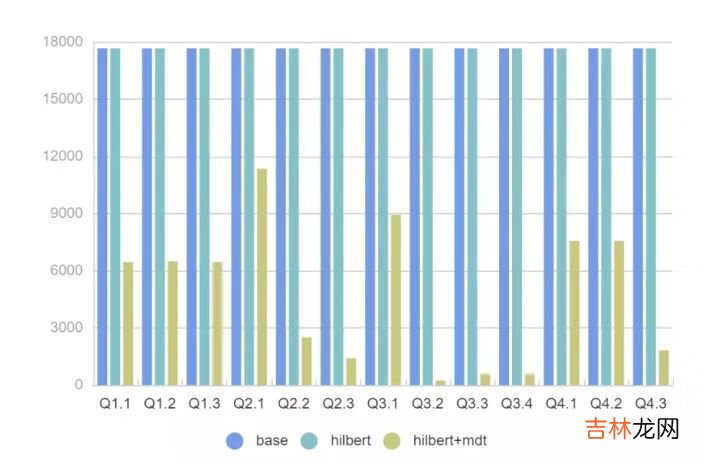
文件读取量
文章插图
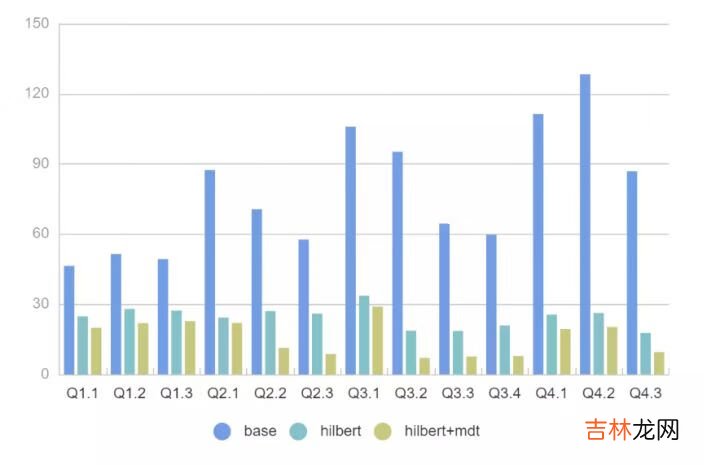
- 对于所有 SQL 我们可以看到 2x - 11x 的性能提升,FileSkipping 效果更加明显过滤掉的文件有 2x - 200x 的提升 。
- 即使没有 MDT,Presto 强大的 Rowgroup 级别过滤,配合 Hilbert 数据布局优化也可以很好地提升查询性能 。
- SSB模型扫描的列数据都比较少,实际场景中如果扫描多个列 Presto + MDT+ Hilbert 的性能可以达到 30x 以上 。
- 测试中同样发现了MDT的不足,120亿数据产生的MDT表有接近50M,加载到内存里面需要一定耗时,后续考虑给MDT配置缓存盘加快读取效率 。
spark.sql( """ |create table prestoc( |c1 int, |c11 int, |c12 int, |c2 string, |c3 decimal(38, 10), |c4 timestamp, |c5 int, |c6 date, |c7 binary, |c8 int |) using hudi |tblproperties ( |primaryKey = 'c1', |preCombineField = 'c11', |hoodie.upsert.shuffle.parallelism = 8, |hoodie.table.keygenerator.class = 'org.apache.hudi.keygen.SimpleKeyGenerator', |hoodie.metadata.enable = "true", |hoodie.metadata.index.column.stats.enable = "true", |hoodie.metadata.index.column.stats.file.group.count = "2", |hoodie.metadata.index.column.stats.column.list = 'c1,c2', |hoodie.metadata.index.bloom.filter.enable = "true", |hoodie.metadata.index.bloom.filter.column.list = 'c1', |hoodie.enable.data.skipping = "true", |hoodie.cleaner.policy.failed.writes = "LAZY", |hoodie.clean.automatic = "false", |hoodie.metadata.compact.max.delta.commits = "1" |) | |""".stripMargin)最终一共产生了8个文件,结合 BloomFilter Skipping掉了7 个,效果非常明显 。
后续工作后续关于点查这块工作会重点关注 Bitmap 以及二级索引 。最后总结一下 DataSkipping 中各种优化技术手段的选择方式 。
- Clustering中各种排序方式需要结合 Column statistics 才能达到更好的效果 。
- BloomFilter 适合等值条件点查,不需要数据做排序,但是要选择高基字段,低基字段 BloomFIlter 用处不大;另外超高基也不要选 BloomFilter,产出的 BloomFilter 结果太大 。
经验总结扩展阅读


















- 14 基于SqlSugar的开发框架循序渐进介绍-- 基于Vue3+TypeScript的全局对象的注入和使用
- 【Python+C#】手把手搭建基于Hugging Face模型的离线翻译系统,并通过C#代码进行访问
- 基于Qt Designer和PyQt5的桌面软件开发--环境搭建和入门例子
- 域名的由来
- www服务基于什么协议
- 背叛这个词 被背叛了,我们应该基于这几个原则性问题,做出自己的抉择
- 什么是g大调 g大调是什么
- 微博是干什么用的
- 超级sim卡是什么意思
- 越是长大 很多男人对一个女人的了解,那都只会基于表面,并不会有太多