布隆过滤器原理介绍【1】概念说明
1)布隆过滤器(Bloom Filter)是1970年由布隆提出的 。它实际上是一个很长的二进制向量和一系列随机映射函数 。布隆过滤器可以用于检索一个元素是否在一个集合中 。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难 。
【2】设计思想
1)BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构 。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列 。
2)当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值 。以哈希值作为位数组中的下标,将所有k个对应的比特置为1 。
3)当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特 。如果有任意一个比特为0,表明该元素一定不在集合中 。如果所有比特均为1,表明该集合有(较大的)可能性在集合中 。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false positive) 。相对地,“假阴性”(false negative)在BF中是绝不会出现的 。
【3】图示
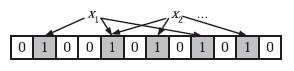
文章插图
【4】优缺点
1)优点
1.不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
2.时间效率也较高,插入和查询的时间复杂度均为O(k);
3.哈希函数之间相互独立,可以在硬件指令层面并行计算 。
2)缺点
1.存在假阳性的概率,不适用于任何要求100%准确率的情境;
2.只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的 。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中 。(因此只能进行重建)
guava框架如何实现布隆过滤器【1】引入依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.0-jre</version></dependency>【2】简单使用
//布隆过滤器-数字指纹存储在当前jvm当中public class LocalBloomFilter {private static final BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8),1000000,0.01);/*** 谷歌guava布隆过滤器* @param id* @return*/public static boolean match(String id){return bloomFilter.mightContain(id);}public static void put(Long id){bloomFilter.put(id+"");}}【3】源码分析(由上面的三个主要方法看起,create方法,mightContain方法,put方法)
1)create方法深入分析
@VisibleForTestingstatic <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {//检测序列化器checkNotNull(funnel);//检测存储容量checkArgument(expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);//容错率应该在0-1之前checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);//检测策略checkNotNull(strategy);if (expectedInsertions == 0) {expectedInsertions = 1;}// 这里numBits即底下LockFreeBitArray位数组的长度,可以看到计算方式就是外部传入的期待数和容错率long numBits = optimalNumOfBits(expectedInsertions, fpp);int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);try {return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, strategy);} catch (IllegalArgumentException e) {throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);}}private BloomFilter(BitArray bits, int numHashFunctions, Funnel<? super T> funnel, Strategy strategy) {//检测hash函数个数应该在0-255之间checkArgument(numHashFunctions > 0, "numHashFunctions (%s) must be > 0", numHashFunctions);checkArgument(numHashFunctions <= 255, "numHashFunctions (%s) must be <= 255", numHashFunctions);this.bits = checkNotNull(bits);this.numHashFunctions = numHashFunctions;this.funnel = checkNotNull(funnel);this.strategy = checkNotNull(strategy);}//计算容量大小@VisibleForTestingstatic long optimalNumOfBits(long n, double p) {if (p == 0) {p = Double.MIN_VALUE;}return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));}//计算满足条件时,应进行多少次hash函数@VisibleForTestingstatic int optimalNumOfHashFunctions(long n, long m) {// (m / n) * log(2), but avoid truncation due to division!return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));}
经验总结扩展阅读












- 18 基于.NetCore开发博客项目 StarBlog - 实现本地Typora文章打包上传
- 广州南怎么换乘
- 深入理解AQS--jdk层面管程实现【管程详解的补充】
- Go实现优雅关机与平滑重启
- [s905l3]性价比神机mgv3000全网首拆,刷armbian实现更多价值!
- 2 Libgdx游戏开发——接水滴游戏实现
- 带样式 JSP实现登录删除添加星座等
- 结合springboot实现,这里对接的是easy版本,工具用的是IDEA,WebStrom 支付宝沙箱服务
- Asp-Net-Core开发笔记:集成Hangfire实现异步任务队列和定时任务
- Skywalking Swck Agent注入实现分析