?欢迎来到物联网的数据世界
在典型的物联网场景中,一般有多种不同类型的采集设备,采集多种不同的物理量,同一种采集设备类型,往往有多个设备分布在不同的地点,系统需对各种采集的数据汇总,进行计算和分析对于同一类设备,其采集的数据都是很规则的 。
本文我们以智能电表(采集量为电流、电压)为例,探讨如何在TDengine中建库、建超级表、建表 。
假设每个智能电表采集电流、电压两个量,其采集的数据如下图所示 。
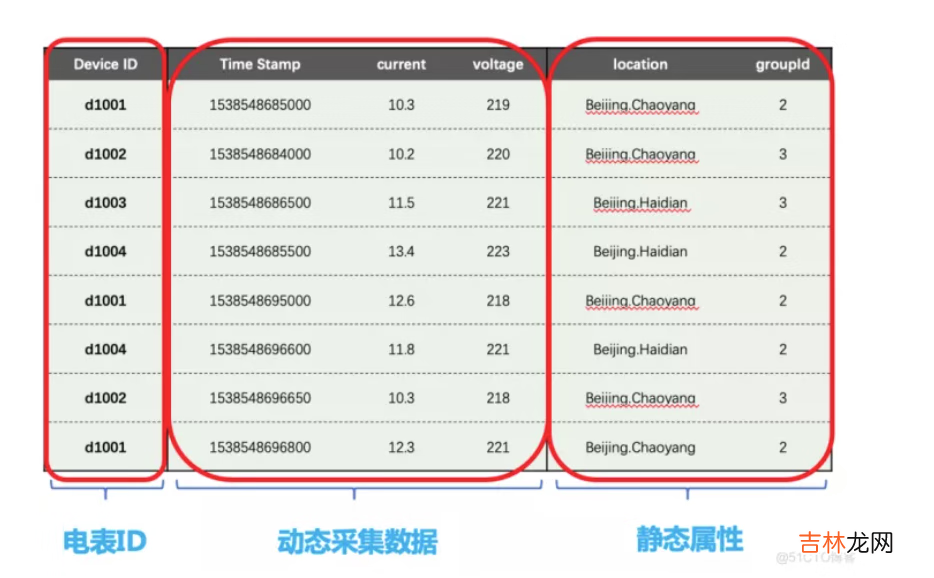
文章插图
每一条记录都有设备ID,时间戳,采集的物理量(如上图中的电流、电压),还有与每个设备相关的静态标签(如上图中的位置Location和分组groupId) 。每个设备是受外界的触发,或按照设定的周期采集数据 。采集的数据点是时序的,是一个数据流 。
那么TDengine如何抽象这些物联网数据呢?
这里,需要提到TDengine的关键创新点——?一个采集点一张表? 。同一类型的采集点用一个超级表来描述,也就是一个表结构Schema和静态标签Schema。就上图来说,电表ID作为子表名(d1001, d1002, d1003, d1004等),动态采集的物理量作为各字段,静态属性(Location和groupId)作为子表标签 。利用超级表作为模板,生成子表 – 对应各采集点,有了超级表,极大地方便了同类采集点的数据检索、查询、聚合 。
这种设计有几大优点:
- 能保证一个采集点的数据在存储介质上是以块为单位连续存储的 。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度 。
- 由于不同采集设备产生数据的过程完全独立,每个设备的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升 。
- 对于一个数据采集点而言,其产生的数据是时序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度 。
?数据建模的基本方法
TDengine采用关系型数据模型,需要建库、建表 。因此对于一个具体的应用场景,需要考虑库的设计,超级表和普通表的设计 。
CREATE DATABASE dbnameUSE dbnameCREATE TABLE stbname (ts timestamp, other fields…) tags ( tag fields)CREATE TABLE tbname using stbname tags(具体标签值)INSERT INTO tbname VALUES(now, values…)实例
INSERT INTO ${tableName} USING xm_values (groupId) TAGS (2)VALUES<foreach collection="paramList" item="param"separator=",">(#{param.time_new},#{param.stid},null,#{param.value},#{param.sblx},#{param.time},#{param.homeRoom},#{param.friendlyName})</foreach>创建库
不同类型的数据采集点往往具有不同的数据特征,包括数据采集频率的高低,数据保留时间的长短,副本的数目,数据块的大小等 。为让各种场景下TDengine都能最大效率的工作,建议将不同数据特征的表创建在不同的库里,因为每个库可以配置不同的存储策略 。
创建一个库时,除SQL标准的选项外,应用还可以指定保留时长、副本数、内存块个数、时间精度、文件块里最大最小记录条数、是否压缩、一个数据文件覆盖的天数等多种参数 。比如建议为数据特征相同的表创建一个库,每个库可以配置不同的存储策略 。
经验总结扩展阅读










- 牛仔裤的清洁方法
- 利用Pandas处理数据 缺失值的处理 数据库的使用 python-数据描述与分析2
- 基于Netty的TCP服务框架
- 常用的论证方法有哪些
- 什么花花语是错过的爱
- 用电器是将什么能转化成什么能
- Docker | 镜像浅析,以及制作自己的镜像
- 车公庙丰盛町有什么好吃的
- 贫血食补补什么
- 禁止焦虑的签名短句 引人深思的好听签名