命令传播:主节点和从节点保持连接,主节点将继续向从节点发送命令流,保证主节点上的数据集发生了变更同样在从数据集上也发生变更 。流程图:
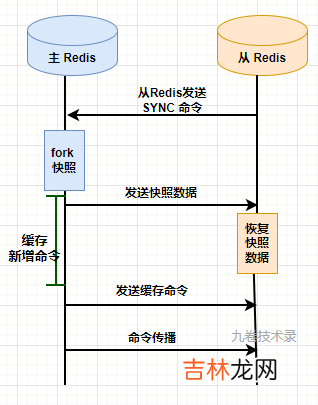
文章插图
3.3 Redis2.8之后复制
以 redis6.0 版本来介绍 。Redis2.8 之后全量复制与上面(Redis2.8之前)复制步骤差不多,SYNC 命令变成了 PSYNC 命令,之后增加了部分重同步 。部分重同步改进了之前的每次需要全量同步问题 。
增加了部分重同步,这个要怎么做才能兼容之前的全量同步呢?怎么知道从库复制到哪儿了?第一个从库肯定要记录下从库复制到哪儿了,下次断线重连时就可以告诉主库该从哪个地方开始复制了 。主库也要记录自己的一些复制信息 。Redis 用了几个概念就把这些问题给解决了,Replication ID,offset,replication_backlog 。
- Replication ID:复制 ID 。这是一个较大的随机字符串,标记一个给定的数据集 。每个主节点都会用这个 Repli ID 来标识内部数据集,从节点 ID 。当从节点加入时,这个 repli id 就初始化了 。
- offset:复制偏移量 。每个主节点都有这个 offset 偏移量,主节点将自己产生的数据发送给从节点时,发送多少字节数据,自身 offset 就会增加多少 。从节点也有自己 offset,从节点写入数据时,offset 也会增加 。断线重连时,就可以知道从哪里开始同步了 。offset 需配合下面的复制积压缓冲区工作 。
- replication_backlog:复制积压缓冲区 。它是在主节点上的一个环形缓冲区,用来存储主节点向从节点传递的命令 。它是大小固定,存储的命令有限,所有超出了就会删除 。从节点进行增量同步时,主节点会根据 offset 从 replication_backlog 中拷贝从节点缺失的数据到从节点 。
Redis2.8之后就是用上面这几个概念实现部分数据重同步的 。从节点发送主节点的 replid 和从节点的一个 offset,主节点拿到这个replid 和自己的 replid 比较,如果是一样,并且这个 offset 也在 backlog 中能找到,那就可以可以进行部分重同步 。
全量复制步骤
- 主从节点先建立连接
主节点收到 PSYNC 命令后,会用 FULLRESYNC 命令响应,带上主节点的 replid 和 offset 返回给从库,从库会记录下这两个参数 。便于以后判断是否需要部分重同步 。
- 同步数据
- 同步缓冲的命令数据
当主库把 RDB 文件传送给从节点完成后,就会把 replication buffer 中的写命令操作发送给从节点,从节点执行这些操作命令,主从节点同步完成 。