之后会继续向从节点发送主节点的操作命令,从节点执行这些命令,保持主从数据的一致 。
上面是一个主体的同步步骤,更加详细的步骤要分析源码了 。
发送步骤与 Redis2.8 之前全量同步没有多大区别 。
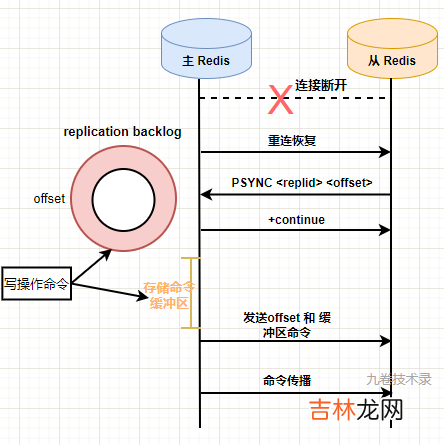
部分数据同步部分数据同步,解决的是主从节点在同步命令时候,网络断了在连上时,Redis2.8 之前会在全量同步数据,显然开销太大,不合理 。能不能只把断线后的数据同步一份,而不是全量同步?
网络断线后,就有部分命令数据没有同步到从节点上去,那我们能不能保存这部分命令数据?重连后,将断开期间的这部分命令重新同步给从节点,这样就不需要全量同步 。
Redis2.8 之后引入了 replication_backlog 复制积压缓冲区,前面有讲到这个概念 。命令一方面会传输给从节点,另外还会记录在这个复制积压缓冲区里 。Redis 使用一个环形缓冲区的结构保存最近的一些命令 。在缓冲区中,对字节进行编号,这个编号在 Redis 中叫复制偏移量 。

文章插图
是否部分同步条件?
- 从节点 replid 和 主节点的 replid 相同
- 复制偏移量 offset 在复制积压缓冲区的 backlog_off 和 offset 范围之间 。
文章插图
四、Redis4.0的同源增量同步先看两个问题
1.从节点重启后丢失了原主节点的节点编号和复制偏移量,这导致重启后需要全量复制,这个很好办,把这些信息保存下来
2.主从切换后,主节点信息变化了,导致从节点需要全量数据同步,这个也好办,只要能确认新主节点数据是从原主节点复制过来就可以了
Redis4.0 后,对 PSYNC 进行了改进,提出了同源增量复制解决方案,来解决上面提到的两个全量复制问题 。
第1个:从节点重启后,需要跟主节点全量数据同步,为什么?本质原因,是从节点丢失了主节点的编号信息和偏移量信息 。Redis4.0后,就把主节点的编号信息写入到 RDB 中持久化保存 。
第2个:主从切换后,从节点需要和主节点全量同步,为什么?原因就是新的主节点不认识原来主节点的编号信息 。切换后怎么才能识别到呢?Redis4.0 后,主从切换后,新的主节点会将先前的主节点信息记录下来,这样新主节点就知道自己原先数据是从哪个旧主节点同步来的,大家都是从同一个地方出来的,应该接受部分数据同步策略 。
五、Redis6.0无盘同步复制什么叫无盘?
原先的同步复制是通过 fork 一个子进程生成 RDB 快照文件,RDB 存储在磁盘上,然后传输 RDB 文件,从节点服务器在恢复 RDB 文件数据 。
无盘,就是说不生成 RDB 文件,不通过 RDB 来传输数据 。而是直接通过网络来传输数据 。
怎么做到无盘呢?
Redis6.0 后,它也是先 fork 一个子进程,这个子进程 dump 数据,它通过管道回写给主节点,主节点在将数据发送给从节点,这样的过程就是无盘传输 。
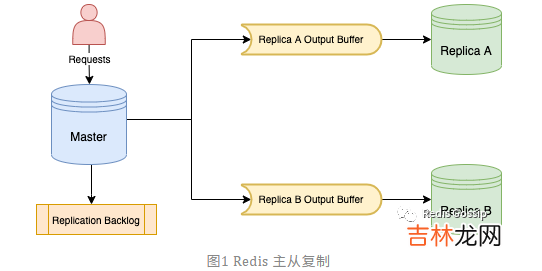
六、Redis7.0共享复制缓冲区6.1 多从库时主库占用内存过多问题
文章插图
(from: https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT)
如图所示,对于 Redis 主库,当用户的写请求到达时,主库会将变更命令分别写入所有从库的缓冲区(OutputBuffer),以及复制积压缓冲区(ReplicationBacklog) 。全量同步也会执行该逻辑 。所以在全量同步阶段经常会触发 client-output-buffer-limit,主库断开与从库的连接,导致主从同步失败,甚至出现循环持续失败的情况 。经验总结扩展阅读
- flinksql读写redis
- 追求性能极致:Redis6.0的多线程模型
- 水银温度计用之前要甩一甩吗 体温计不甩量的体温会怎么样
- spring boot集成redis基础入门
- CentOS 7.9 安装 redis-6.2.0
- Redis实现布隆过滤器解析
- 242的身高可以扣篮吗
- 18-基于CentOS7搭建RabbitMQ3.10.7集群镜像队列+HaProxy+Keepalived高可用架构
- 深入底层C源码 Redis核心设计原理
- Redis高并发分布式锁详解








