vivo 互联网产品团队 - Wang xiao随着广告和内容等推荐场景的扩展 , 算法模型也在不断演进迭代中 。业务的不断增长 , 模型的训练、产出迫切需要进行平台化管理 。vivo互联网机器学习平台主要业务场景包括游戏分发、商店、商城、内容分发等 。本文将从业务场景、平台功能实现两个方面介绍vivo内部的机器学习平台在建设与实践中的思考和优化思路 。
一、写在前面随着互联网领域的快速发展 , 数据体量的成倍增长以及算力的持续提升 , 行业内都在大力研发AI技术 , 实现业务赋能 。算法业务往往专注于模型和调参 , 而工程领域是相对薄弱的一个环节 。建设一个强大的分布式平台 , 整合各个资源池 , 提供统一的机器学习框架 , 将能大大加快训练速度 , 提升效率 , 带来更多的可能性 , 此外还有助于提升资源利用率 。希望通过此文章 , 初学者能对机器学习平台 , 以及生产环境的复杂性有一定的认识 。
二、业务背景截止2022年8月份 , vivo在网用户2.8亿 , 应用商店日活跃用户数7000万+ 。AI应用场景丰富 , 从语音识别、图像算法优化、以及互联网常见场景 , 围绕着应用商店、浏览器、游戏中心等业务场景的广告和推荐诉求持续上升 。
如何让推荐系统的模型迭代更高效 , 用户体验更好 , 让业务场景的效果更佳 , 是机器学习平台的一大挑战 , 如何在成本、效率和体验上达到平衡 。
从下图可以了解到 , 整个模型加工运用的场景是串行可闭环的 , 对于用户的反馈需要及时进行特征更新 , 不断提升模型的效果 , 基于这个链路关系的基础去做效率的优化 , 建设一个通用高效的平台是关键 。
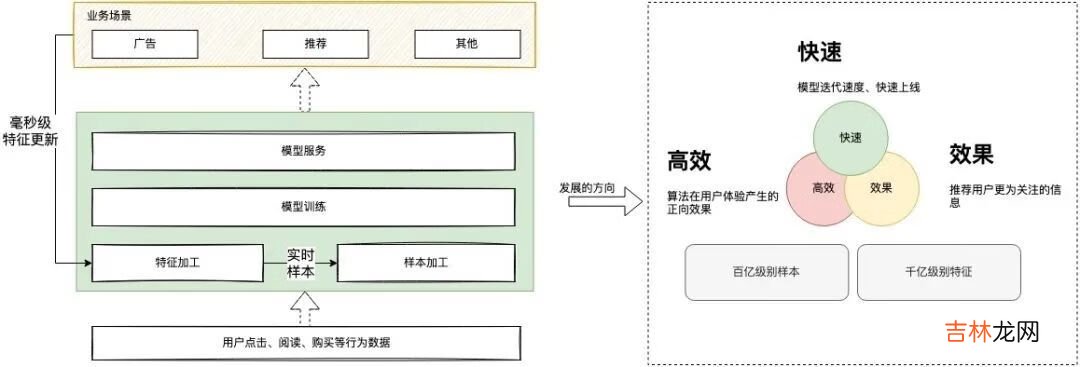
文章插图
三、vivo机器学习平台的设计思路3.1 功能模块基于上图业务场景的链路关系 , 我们可以对业务场景进行归类 , 根据功能不同 , 通用的算法平台可划分为三步骤:数据处理「对应通用的特征平台 , 提供特征和样本的数据支撑」、模型训练「对应通用的机器学习平台 , 用于提供模型的训练产出」、模型服务「对应通用的模型服务部署 , 用于提供在线模型预估」 , 三个步骤都可自成体系 , 成为一个独立的平台 。
本文将重点阐述模型训练部分 , 在建设vivo机器学习平台过程中遇到的挑战以及优化思路 。
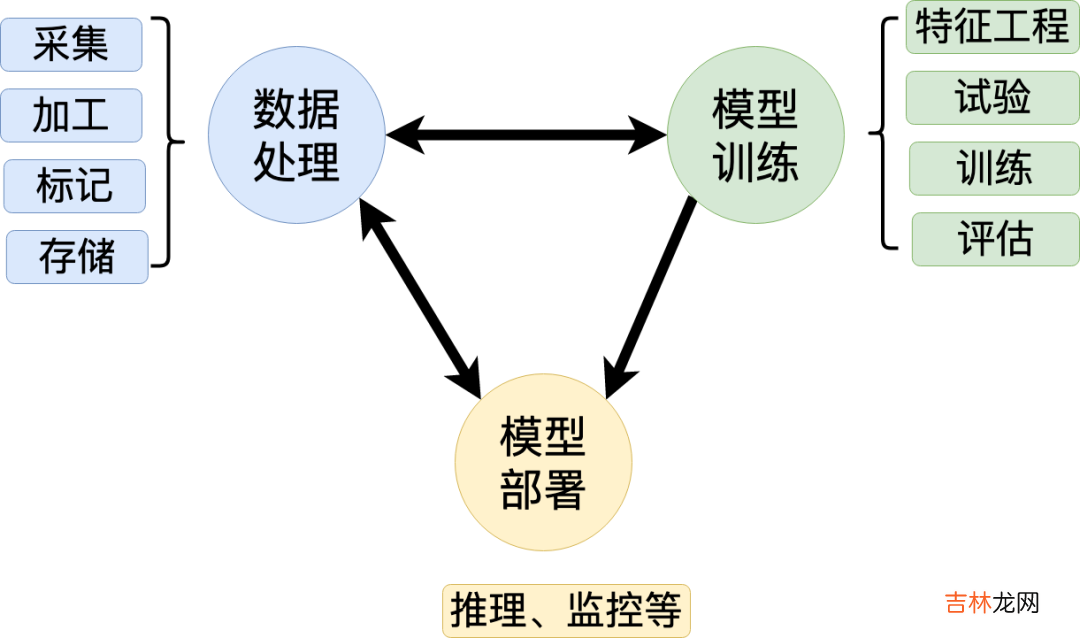
文章插图
1.数据处理 , 围绕数据相关的工作 , 包括采集、加工、标记和存储 。
其中 , 采集、加工、存储与大数据平台的场景相吻合 , 标记场景是算法平台所独有的 。
- 数据采集 , 即从外部系统获得数据 , 使用Bees{vivo数据采集平台}来采集数据 。
- 数据加工 , 即将数据在不同的数据源间导入导出 , 并对数据进行聚合、清洗等操作 。
- 数据标记 , 是将人类的知识附加到数据上 , 产生样本数据 , 以便训练出模型能对新数据推理预测 。
- 数据存储 , 根据存取的特点找到合适的存储方式 。
经验总结扩展阅读












- 2023年10月17日安机器吉日一览表 2023年10月17日是安机器的黄道吉日吗
- 2023年10月17日是安装机器的黄道吉日吗 2023年农历九月初三宜安装机器吗
- 2023年农历正月廿四安机器吉日 2023年2月14日安机器黄道吉日
- 2023年2月14日安装机器行吗 2023年2月14日是安装机器的黄道吉日吗
- 实时营销引擎在vivo营销自动化中的实践 | 引擎篇04
- vivoX70pro和苹果11区别对比_哪款更值得入手
- vivox70pro+和小米11Ultra那个好_详细对比
- vivo手机换卡时需要关机吗
- vivoz1激活手机显示网络连接异常
- vivo手机怎么设置网关