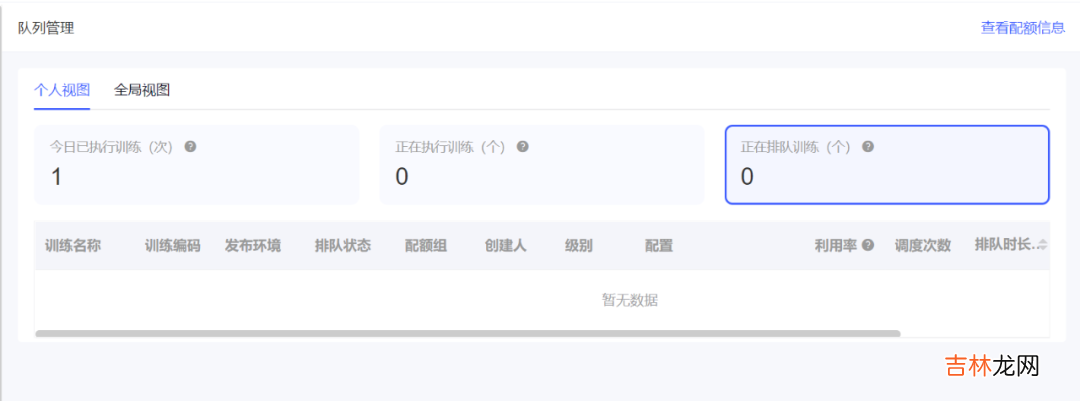
围绕并不限于以下维度:最大运行时长、排队时长、cpu&内存&gpu颗粒度和总需求量等 。
文章插图
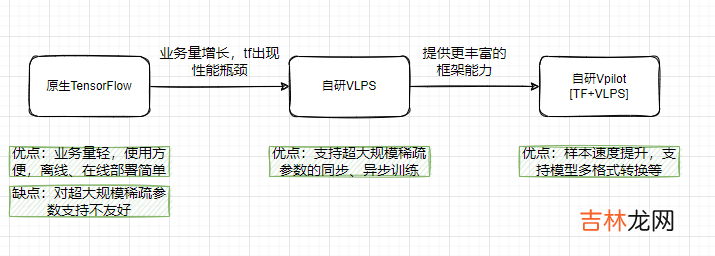
4.2.2 框架自研痛点:
随着样本和特征规模增加后 , 框架的性能瓶颈凸显 , 需要提升推理计算的效率 。
发展路径:
每一次的发展路径主要基于业务量的发展 , 寻求最佳的训练框架 , 框架的每一次版本升级都打包为镜像 , 支持更多模型训练 。
文章插图
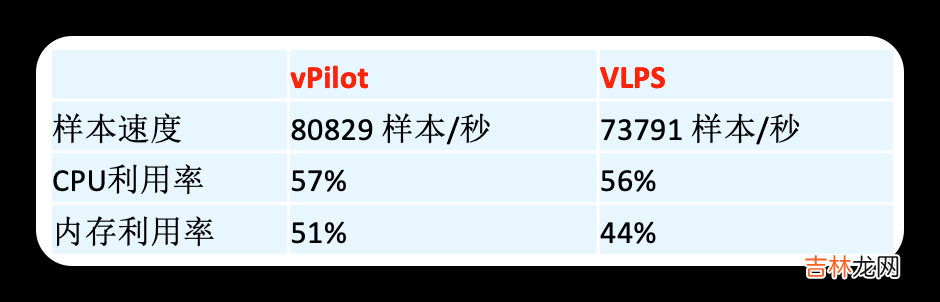
当前效果:
文章插图
4.2.3 训练管理痛点:
如何支持多种分布式训练框架 , 满足算法工程师的业务诉求 , 让用户无需关心底层机器调度和运维;如何让算法工程师快速新建训练 , 执行训练 , 可查看训练状态 , 是训练管理的关键 。
解决思路:
上传代码至平台的文件服务器和git都可以进行读取 , 同时在平台填写适量的参数即可快速发起分布式训练任务 。同时还支持通过OpenAPI , 便于开发者在脱离控制台的情况下也能完成机器学习业务 。
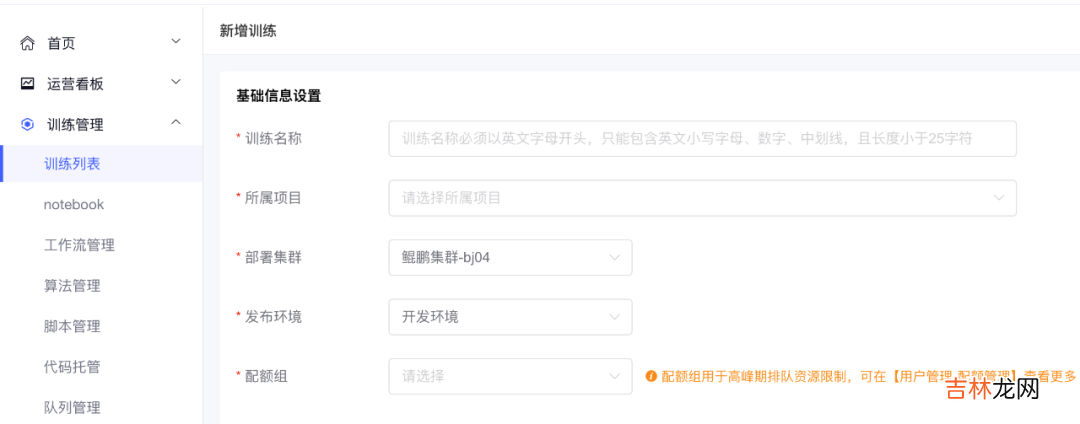
围绕训练模型相关的配置信息 , 分为基础信息设置、资源信息设置、调度依赖设置、告警信息设置和高级设置 。在试验超参的过程中 , 经常需要对一组参数组合进行试验 。
批量提交任务能节约使用者时间 。平台也可以将这组结果直接进行比较 , 提供更友好的界面 。训练读取文件服务器或git的脚本 , 即可快速执行训练 。
1.可视化高效创建训练
文章插图
2. 准确化快速修改脚本
文章插图
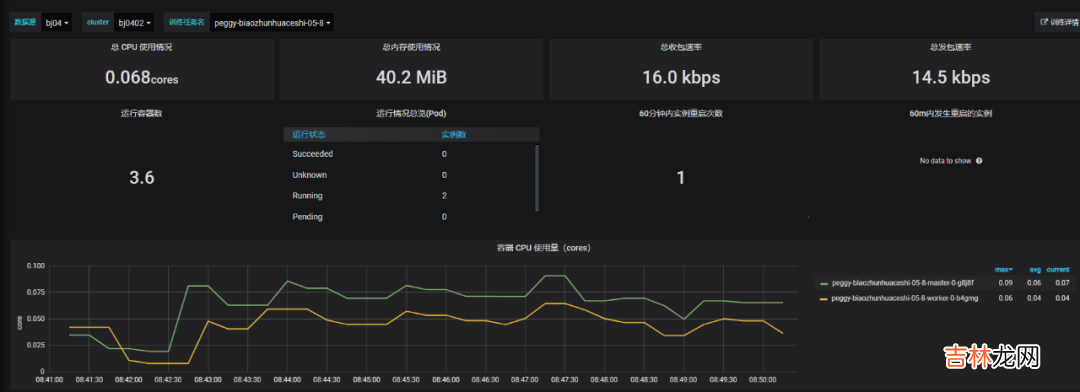
3. 实时化监控训练变动
文章插图
4.2.4 交互式开发痛点:
算法工程师调试脚本成本较高 , 算法工程师和大数据工程师有在线调试脚本的诉求 , 可直接通过浏览器运行代码 , 同时在代码块下方展示运行结果 。
解决思路:
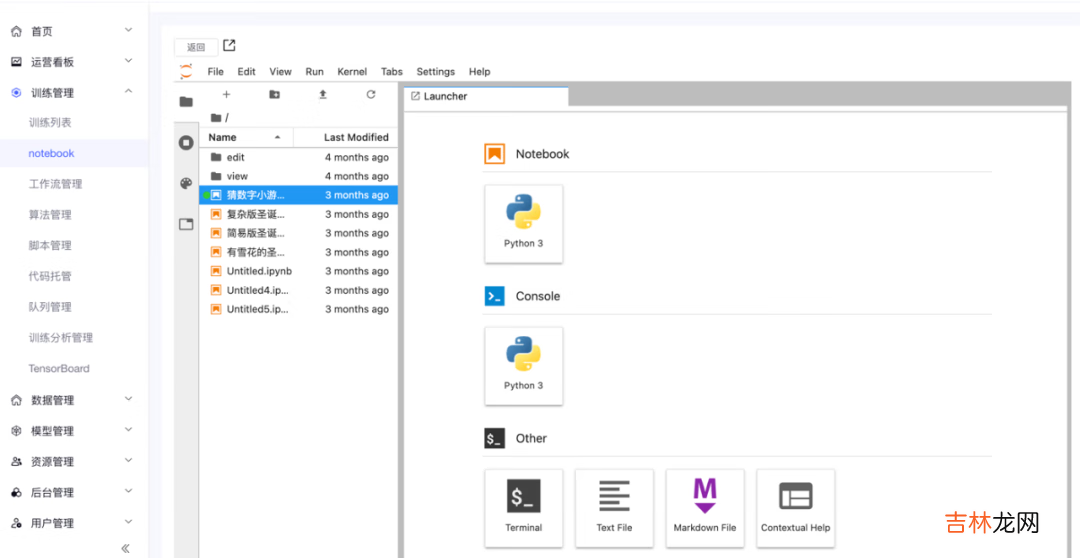
在交互式工具中进行试验、开发 , 如:jupyter notebook , 提供所见即所得的交互式体验 , 对调试代码的过程非常方便 。
在交互试验的场景下 , 需要独占计算资源 。机器学习平台需要提供能为用户保留计算资源的功能 。如果计算资源有限 , 可对每个用户申请的计算资源总量进行限制 , 并设定超时时间 。
例如 , 若一周内用户没有进行资源使用后 , 就收回保留资源 。在收回资源后 , 可继续保留用户的数据 。重新申请资源后 , 能够还原上次的工作内容 。在小团队中 , 虽然每人保留一台机器自己决定如何使用更方便 , 但是用机器学习平台来统一管理 , 资源的利用率可以更高 。团队可以聚焦于解决业务问题 , 不必处理计算机的操作系统、硬件等出现的与业务无关的问题 。
文章插图
五、总结目前vivo机器学习平台支撑了互联网领域的算法离线训练 , 使算法工程师更关注于模型策略的迭代优化 , 从而实现为业务赋能 。未来我们会在以下方面继续探索:
经验总结扩展阅读












- 2023年10月17日安机器吉日一览表 2023年10月17日是安机器的黄道吉日吗
- 2023年10月17日是安装机器的黄道吉日吗 2023年农历九月初三宜安装机器吗
- 2023年农历正月廿四安机器吉日 2023年2月14日安机器黄道吉日
- 2023年2月14日安装机器行吗 2023年2月14日是安装机器的黄道吉日吗
- 实时营销引擎在vivo营销自动化中的实践 | 引擎篇04
- vivoX70pro和苹果11区别对比_哪款更值得入手
- vivox70pro+和小米11Ultra那个好_详细对比
- vivo手机换卡时需要关机吗
- vivoz1激活手机显示网络连接异常
- vivo手机怎么设置网关