然后,在 master 节点先准备好数据
vi data1输入如下数据
{'uid':1,'uname':'grey','dt':'2022/09'}{'uid':2,'uname':'tony','dt':'2022/10'}然后创建文件目录,
hdfs dfs -mkdir /mydata/把 data1 放入目录下
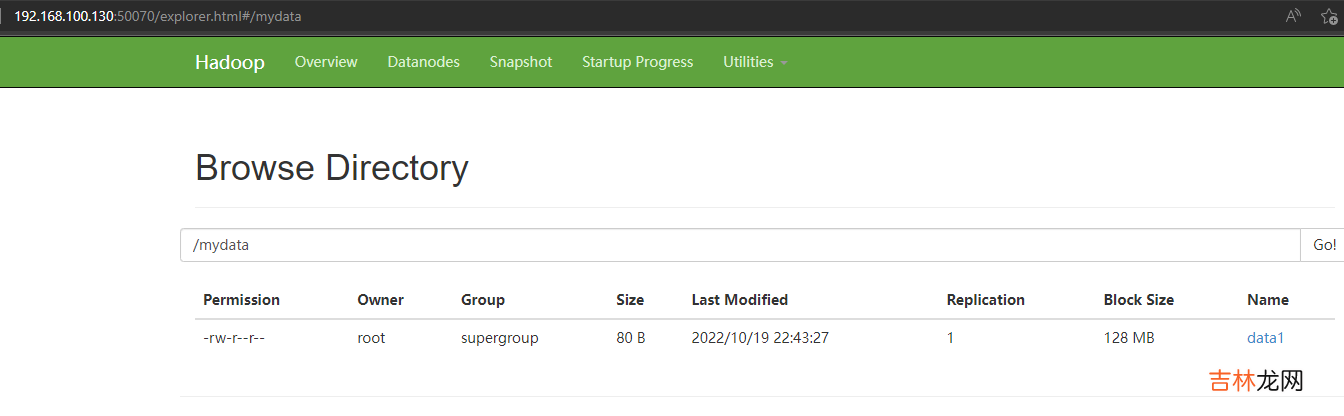
hdfs dfs -put data1 /mydata/访问:http://192.168.100.130:50070/explorer.html#/mydata
可以查到这个数据
文章插图
接下来执行插入数据的 scala 代码,执行完毕后,验证一下
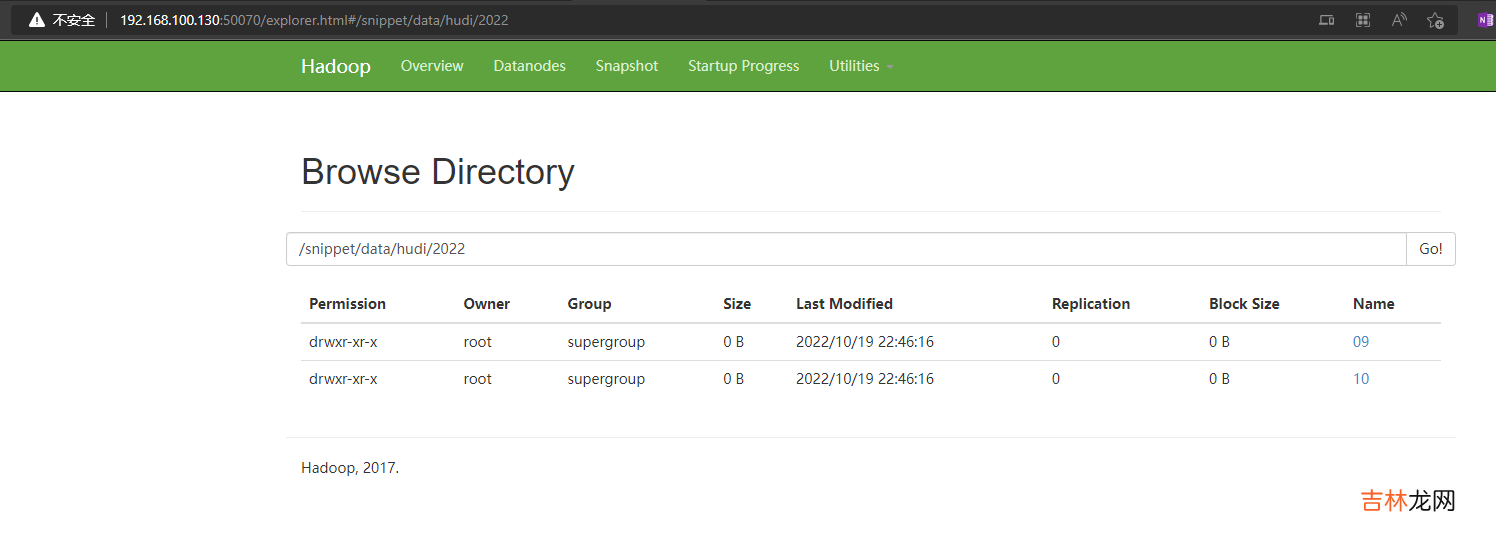
访问:http://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到插入的数据
文章插图
准备一个 data2 文件
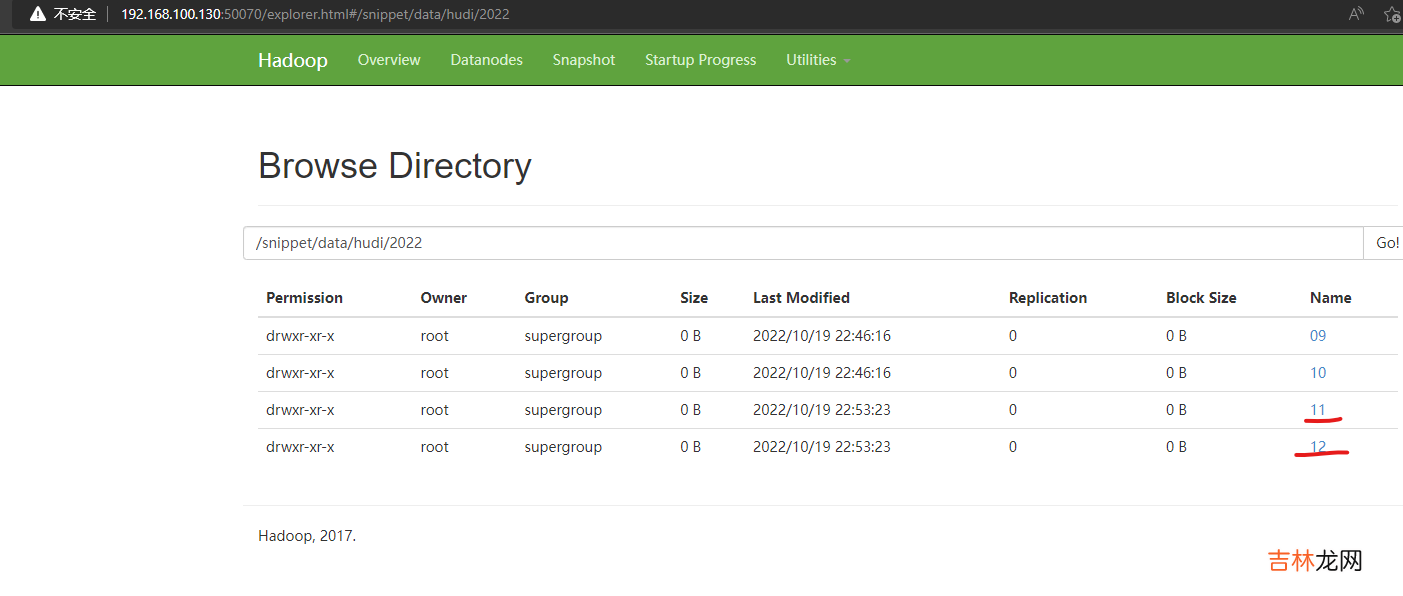
cp data1 data2 && vi data2data2 的数据更新为{'uid':1,'uname':'grey1','dt':'2022/11'}{'uid':2,'uname':'tony1','dt':'2022/12'}然后执行hdfs dfs -put data2 /mydata/更新数据的代码,我们可以做如下调整,完整代码如下package git.snippet.testimport git.snippet.entity.MyEntityimport git.snippet.util.JsonUtilimport org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}import org.apache.spark.SparkConfimport org.apache.spark.sql.{SaveMode, SparkSession}object DataUpdate {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("MyFirstDataApp").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[*]")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")updateData(sparkSession)}def updateData(sparkSession: SparkSession) = {import org.apache.spark.sql.functions._import sparkSession.implicits._val commitTime = System.currentTimeMillis().toString //生成提交时间val df = sparkSession.read.text("/mydata/data2").mapPartitions(partitions => {partitions.map(item => {val jsonObject = JsonUtil.getJsonData(item.getString(0))MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))})})val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列.withColumn("uuid", col("uid")) //添加uuid 列.withColumn("hudipart", col("dt")) //增加hudi分区列result.write.format("org.apache.hudi")//.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL).option("hoodie.insert.shuffle.parallelism", 2).option("hoodie.upsert.shuffle.parallelism", 2).option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列.option("hoodie.table.name", "myDataTable").option("hoodie.datasource.write.partitionpath.field", "hudipart") //分区列.mode(SaveMode.Append).save("/snippet/data/hudi")}}执行更新数据的代码 。验证一下,访问:http://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到更新的数据情况
文章插图
数据查询的代码也很简单,完整代码如下
package git.snippet.testimport org.apache.spark.SparkConfimport org.apache.spark.sql.SparkSessionobject DataQuery {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("MyFirstDataApp").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[*]")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")queryData(sparkSession)}def queryData(sparkSession: SparkSession) = {val df = sparkSession.read.format("org.apache.hudi").load("/snippet/data/hudi/*/*")df.show()println(df.count())}}
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 2023年10月7日是拜观音求子的黄道吉日吗 2023年农历八月廿三宜拜观音求子吗
- 女孩漂亮有涵养的名字大全 有涵养女孩名字
- 吃苏打饼的好处是什么 吃苏打饼坏处有什么
- 带贤字的男孩名字大全 男孩取名名字大全
- 比较诗情画意的女孩名字 女孩名字取名
- 家长怎样培养孩子的社交能力
- 2023年10月7日是祭拜灶神的黄道吉日吗 2023年10月7日祭拜灶神行吗
- 家长在孩子面前吵架的危害
- 女孩漂亮有内涵的名字大全 有内涵名字大全
- 怎么缓解孩子的分离焦虑