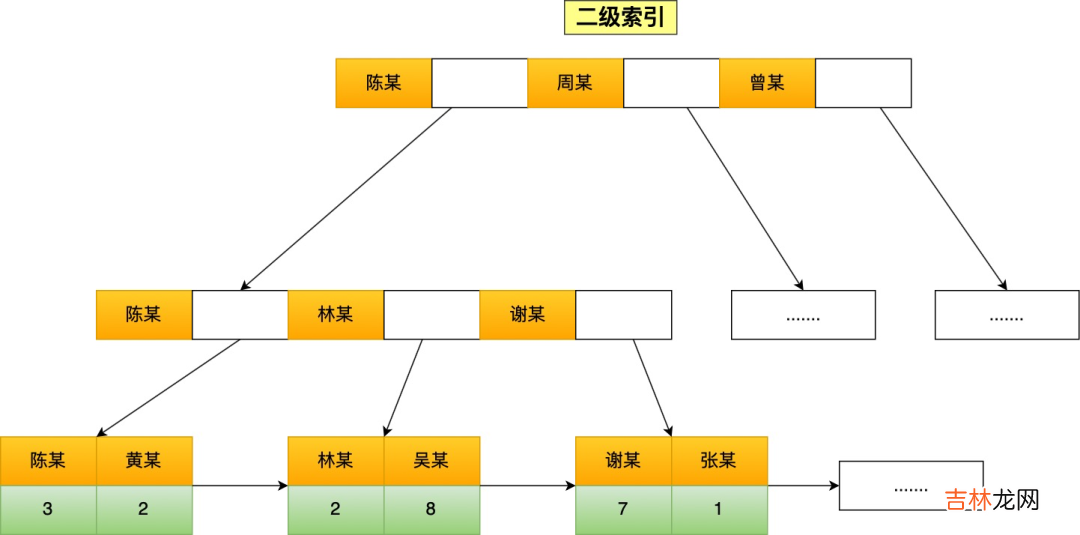
如果将 name 字段设置为普通索引,那么这个二级索引长下图这样,叶子节点仅存放主键值 。
文章插图
知道了 InnoDB 存储引擎的聚簇索引和二级索引的存储结构后,接下来举几个查询语句,说下查询过程是怎么选择用哪个索引类型的 。
在我们使用「主键索引」字段作为条件查询的时候,如果要查询的数据都在「聚簇索引」的叶子节点里,那么就会在「聚簇索引」中的 B+ 树检索到对应的叶子节点,然后直接读取要查询的数据 。如下面这条语句:
// id 字段为主键索引select * from t_user where id=1;在我们使用「二级索引」字段作为条件查询的时候,如果要查询的数据都在「聚簇索引」的叶子节点里,那么需要检索两颗B+树:- 先在「二级索引」的 B+ 树找到对应的叶子节点,获取主键值;
- 然后用上一步获取的主键值,在「聚簇索引」中的 B+ 树检索到对应的叶子节点,然后获取要查询的数据 。
// name 字段为二级索引select * from t_user where name="林某";在我们使用「二级索引」字段作为条件查询的时候,如果要查询的数据在「二级索引」的叶子节点,那么只需要在「二级索引」的 B+ 树找到对应的叶子节点,然后读取要查询的数据,这个过程叫做覆盖索引 。如下面这条语句:// name 字段为二级索引select id from t_user where name="林某";上面这些查询语句的条件都用到了索引列,所以在查询过程都用上了索引 。但是并不意味着,查询条件用上了索引列,就查询过程就一定都用上索引,接下来我们再一起看看哪些情况会导致索引实现,而发生全表扫描 。
首先说明下,下面的实验案例,我使用的 MySQL 版本为
8.0.26 。对索引使用左或者左右模糊匹配当我们使用左或者左右模糊匹配的时候,也就是
like %xx 或者 like %xx% 这两种方式都会造成索引失效 。比如下面的 like 语句,查询 name 后缀为「林」的用户,执行计划中的 type=ALL 就代表了全表扫描,而没有走索引 。
// name 字段为二级索引select * from t_user where name like '%林';
文章插图
如果是查询 name 前缀为林的用户,那么就会走索引扫描,执行计划中的 type=range 表示走索引扫描,key=index_name 看到实际走了 index_name 索引:
// name 字段为二级索引select * from t_user where name like '林%';
文章插图
为什么 like 关键字左或者左右模糊匹配无法走索引呢?因为索引 B+ 树是按照「索引值」有序排列存储的,只能根据前缀进行比较 。
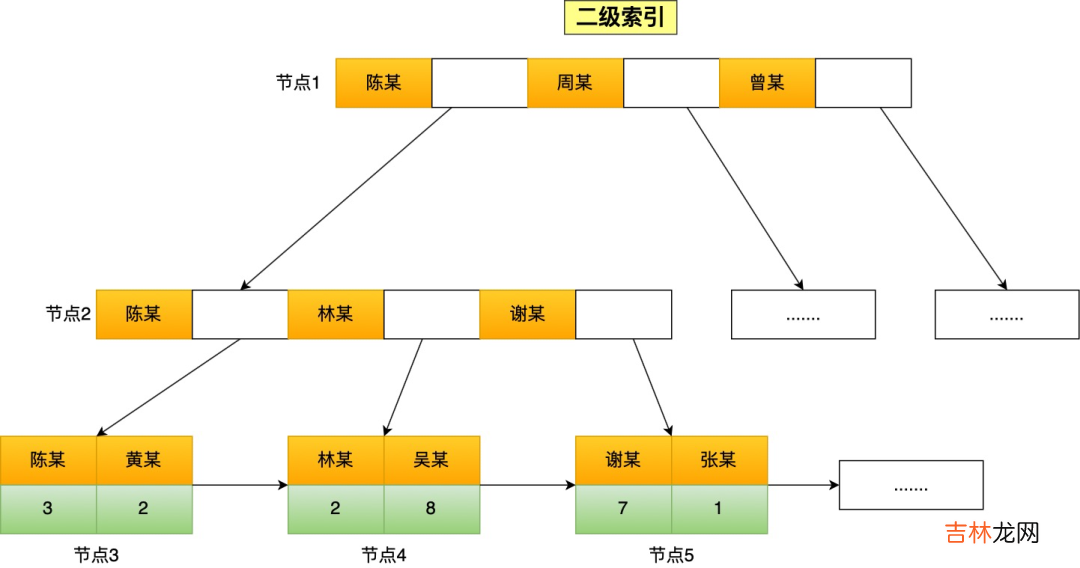
举个例子,下面这张二级索引图,是以 name 字段有序排列存储的 。
文章插图
假设我们要查询 name 字段前缀为「林」的数据,也就是
name like '林%',扫描索引的过程:- 首节点查询比较:林这个字的拼音大小比首节点的第一个索引值中的陈字大,但是比首节点的第二个索引值中的周字小,所以选择去节点2继续查询;
- 节点 2 查询比较:节点2的第一个索引值中的陈字的拼音大小比林字小,所以继续看下一个索引值,发现节点2有与林字前缀匹配的索引值,于是就往叶子节点查询,即叶子节点4;
经验总结扩展阅读
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?
- golang中的nil接收器
- llinux下mysql建库、新建用户、用户授权、修改用户密码
- RedHat7.6安装mysql8步骤
- golang中的字符串
- flutter系列之:flutter中可以建索引的栈布局IndexedStack
- 究极无敌细节版 Mysql索引
- Mysql通过Canal同步Elasticsearch
- MySQL的日志文件
- 01-MySQL8主从详解










