2021-04-09 10:57:40.112999 W | etcdserver: server is likely overloaded
2021-04-09 10:57:43.126444 W | etcdserver: read-only range request "key:\"/Ruby/ignoreNodeNumKey\" " with result "error:context canceled" took too long (1.999877971s) to execute
cd $GAUSSLOG/cm/cm_agent
搜索对应时间点的cm_agent-xxx.log, 如果有如下日志 , 表示当时磁盘io比较高 , io util 100 表示磁盘io 达到100%
2021-04-09 11:06:24.047 tid=15822 LOG: device vdb1, tot_ticks 889640579, cputime 1798651342, io util 100
处理步骤1、在管控面查看该节点当时磁盘IO、CPU、内存监控指标是否很高 ,
示例1:数据盘写延时在16:00左右升高 , 影响etcd状态 。
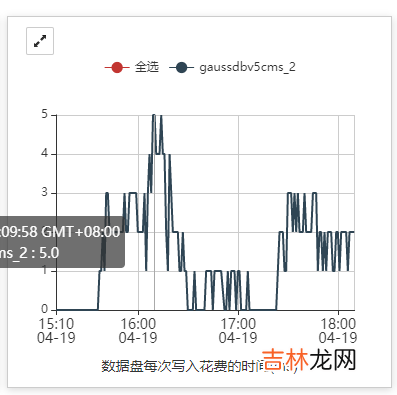
文章插图
示例2: etcd故障时刻 , cpu、内存、磁盘写延时都有增长 , 尤其是磁盘写延时很明显 , 需要分析磁盘写延时升高的原因 。
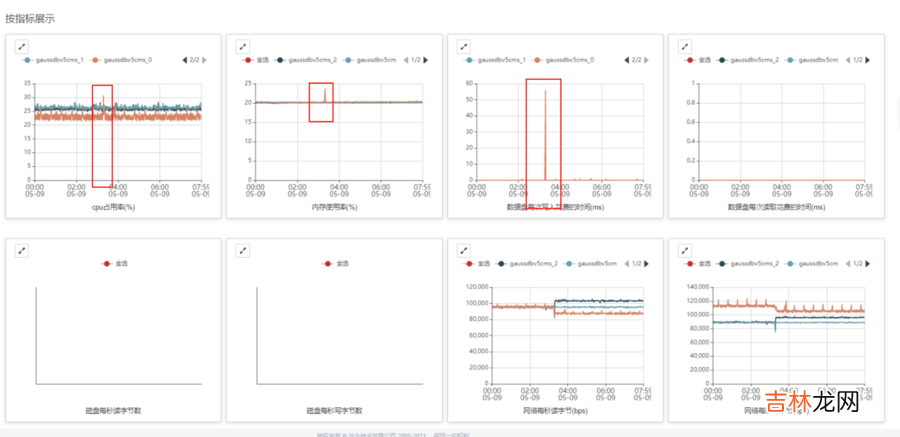
文章插图
2、如果故障现场还在: iostat -mx 1 查看磁盘IO状态 , top和free命令查看cpu、内存使用情况, 分析磁盘IO高、CPU高 , 内存高的原因 。
3、root用户查看该节点的系统日志, cd /var/log, 查看该时间点message日志是否有异常记录 。例如:节点内存耗尽了 , 分析占用内存的原因 , 是否内存泄漏等 。
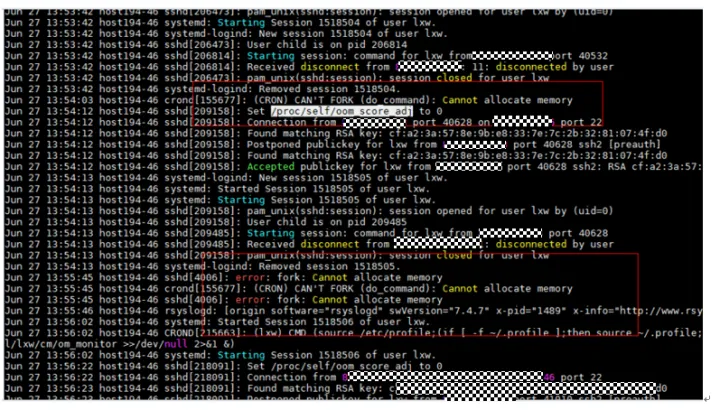
文章插图
如果仍无法确认原因 , 联系华为工程师 。
etcd进程故障导致ETCD服务异常告警问题现象etcd进程down、重启 , 管控面上报etcd服务异常告警
问题分析及界定登陆故障etcd节点 , 进入Ruby用户 , 执行命令ps ux | grep etcd , 查看etcd进程是否在运行 。
如果进程在 , 查看etcd进程启动时间 , 告警时是否重启过 , 联系华为工程师确认重启原因 。

文章插图
如果进程不在 , 查看etcd无法启动原因:
(1)cd $GAUSSLOG/bin, 查看目录下是否有cluster_manual_start 和 etcd_manual_start 两个文件 ,
如果有表示集群被停止 , 确认停止集群的原因 , 之后启动集群 , 定位结束 。
(2)cd $GAUSSHOME/bin 查看目录下是否存在etcd这个文件 , 文件权限是否正确 , 确认文件不存在或权限不正确的原因 。
(3)检查etcd的数据目录所在磁盘是否满了或者故障 , etcd目录如下:cm_ctl query -Cvipd查看
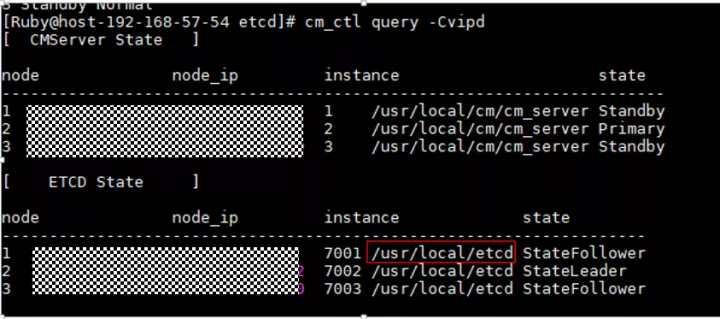
文章插图
检查etcd的数据目录所在磁盘是否满了或者目录权限不正确(正确是700)或者故障 ,
如果磁盘满 , 检查占用磁盘的文件并清除或者转存到其他盘 , 如果是etcd本身的文件占满 , 联系华为工程师分析原因 。
如果目录权限不正确 , 修改为正确的目录权限 。如果是磁盘故障 , 联系IaaS技术支持分析定位 。
处理步骤参照上述处理 , 如果不是以上原因 , 请联系华为工程师
OM接口无法正确返回结果导致ETCD服务异常告警问题现象管控面上报etcd服务异常告警 , 管控无法获取集群状态
问题分析及界定查看管控面是否获取集群状态成功 , 是否获取空消息 , 联系华为工程师分析定位 。
cd $GAUSSLOG/om/
查看gs_om-xxx.log , 是否有如下异常日志
经验总结扩展阅读
















- 手把手教你使用LabVIEW实现Mask R-CNN图像实例分割
- 如何解读Linux Kernel OOPS信息
- 【pytest官方文档】解读-开发可pip安装的第三方插件
- 跟我学Python图像处理丨图像特效处理:毛玻璃、浮雕和油漆特效
- GLA 论文解读《Label-invariant Augmentation for Semi-Supervised Graph Classification》
- 2023年电气工程及其自动化专业大学排名及电气工程及其自动化专业解读
- GGD 论文解读《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
- ULID规范解读与实现原理
- Python地图栅格化实例
- 钩子 【pytest官方文档】解读-插件开发之hooks 函数