官方文档:https://docs.taosdata.com/get-started/package/ 点击进入
产品简介TDengine 是一款高性能、分布式、支持 SQL 的时序数据库 (Database),其核心代码,包括集群功能全部开源(开源协议,AGPL v3.0) 。TDengine 能被广泛运用于物联网、工业互联网、车联网、IT 运维、金融等领域 。除核心的时序数据库 (Database) 功能外,TDengine 还提供缓存、数据订阅、流式计算等大数据平台所需要的系列功能,最大程度减少研发和运维的复杂度 。
本章节介绍TDengine的主要功能、竞争优势、适用场景、与其他数据库的对比测试等等,让大家对TDengine有个整体的了解 。
优势
- 能保证一个采集点的数据在存储介质上是以块为单位连续存储的 。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度 。
- 由于不同采集设备产生数据的过程完全独立,每个设备的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升 。
- 对于一个数据采集点而言,其产生的数据是时序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度 。
- 写入数据,支持
- SQL 写入
- 无模式(Schemaless)写入,支持多种标准写入协议
- InfluxDB Line 协议
- OpenTSDB Telnet 协议
- OpenTSDB JSON 协议
- 与多种第三方工具的无缝集成,它们都可以仅通过配置而无需任何代码即可将数据写入 TDengine
- Telegraf
- Prometheus
- StatsD
- collectd
- Icinga2
- TCollector
- EMQX
- HiveMQ
- 查询数据,支持
- 标准 SQL,含嵌套查询
- 时序数据特色函数
- 时序数据特色查询,例如降采样、插值、累加和、时间加权平均、状态窗口、会话窗口等
- 用户自定义函数(UDF)
- 缓存,将每张表的最后一条记录缓存起来,这样无需 Redis 就能对时序数据进行高效处理
- 流式计算(Stream Processing),TDengine 不仅支持连续查询,还支持事件驱动的流式计算,这样在处理时序数据时就无需 Flink 或 Spark 这样流式计算组件
- 数据订阅,应用程序可以订阅一张表或一组表的数据,提供与 Kafka 相同的 API,而且可以指定过滤条件
- 可视化
- 支持与 Grafana 的无缝集成
- 支持与 Google Data Studio 的无缝集成
- 集群
- 集群部署,可以通过增加节点进行水平扩展以提升处理能力
- 可以通过 Kubernetes 部署 TDengine
- 通过多副本提供高可用能力
- 管理
- 监控运行中的 TDengine 实例
- 多种数据导入方式
- 多种数据导出方式
- 工具
- 提供交互式命令行程序(CLI),便于管理集群,检查系统状态,做即席查询
- 提供压力测试工具 taosBenchmark,用于测试 TDengine 的性能
- 编程
- 提供各种语言的连接器(Connector): 如 C/C++、Java、Go、Node.js、Rust、python/" rel="external nofollow noreferrer">Python、C# 等
- 支持 REST 接口
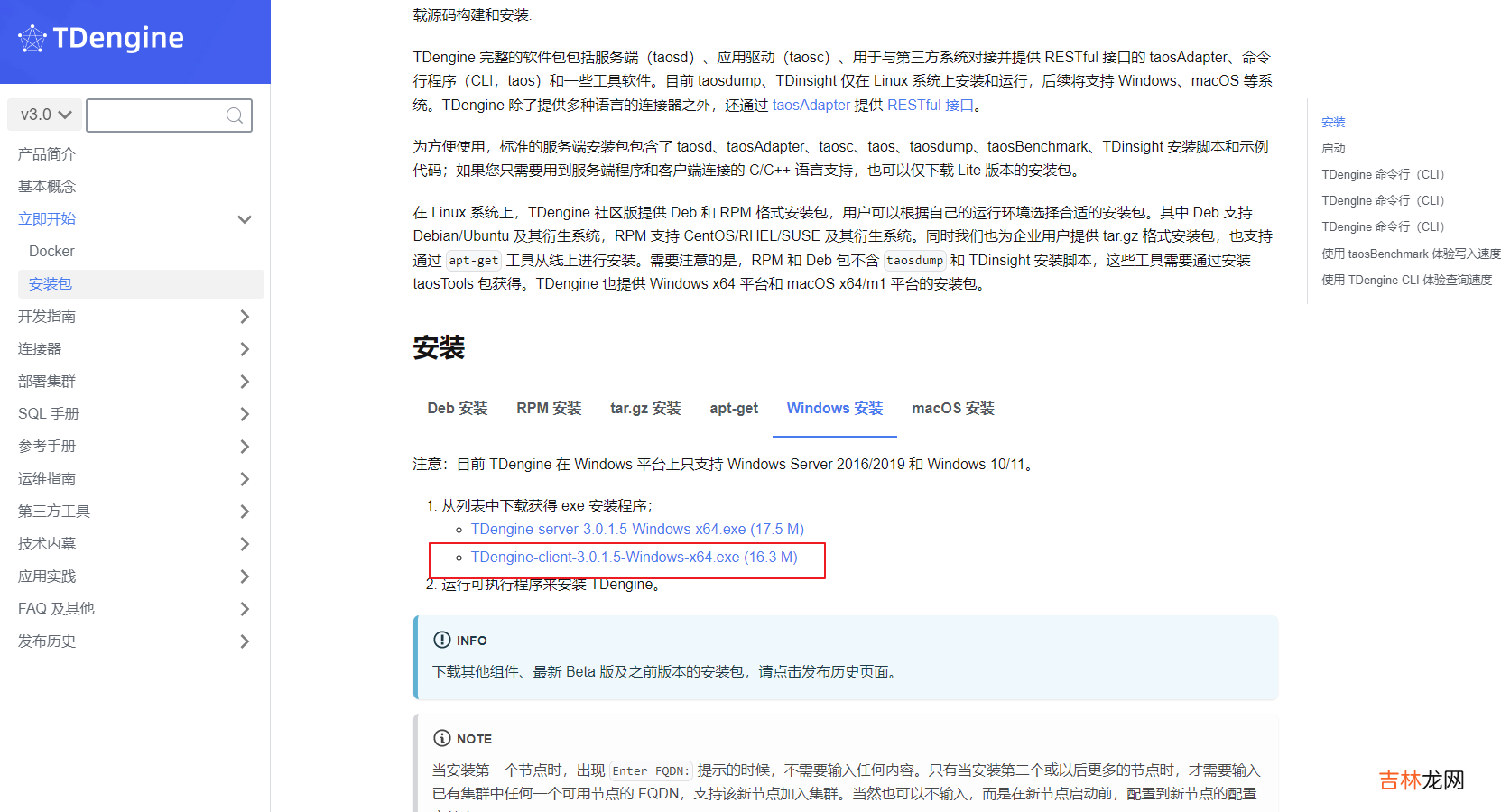
一、下载安装包
因为公司已经在180上部署了,3.0的服务端,所以这里只下载3.0的服务端就可以了
文章插图
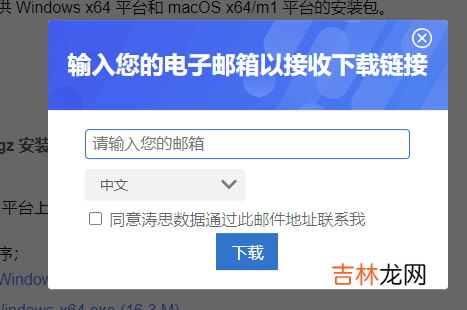
输入邮箱,会将下载地址通过邮件发送给你
文章插图
二、安装时,全部选择默认,下一步下一步就可以
三、安装完后,可能会遇到的一些问题及解决方案
经验总结扩展阅读
















- 云数据库时代,DBA将走向何方?
- 我的Vue之旅 09 数据数据库表的存储与获取实现 Mysql + Golang
- Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务
- MongoDB数据库新手入门
- 一篇文章带你了解NoSql数据库——Redis简单入门
- AgileBoot - 如何集成内置数据库H2和内置Redis
- Windows 环境搭建 PostgreSQL 逻辑复制高可用架构数据库服务
- Oracle数据库的两种授权收费方式介绍!
- Redis 01: 非关系型数据库 + 配置Redis
- sql语法巧用之not取反