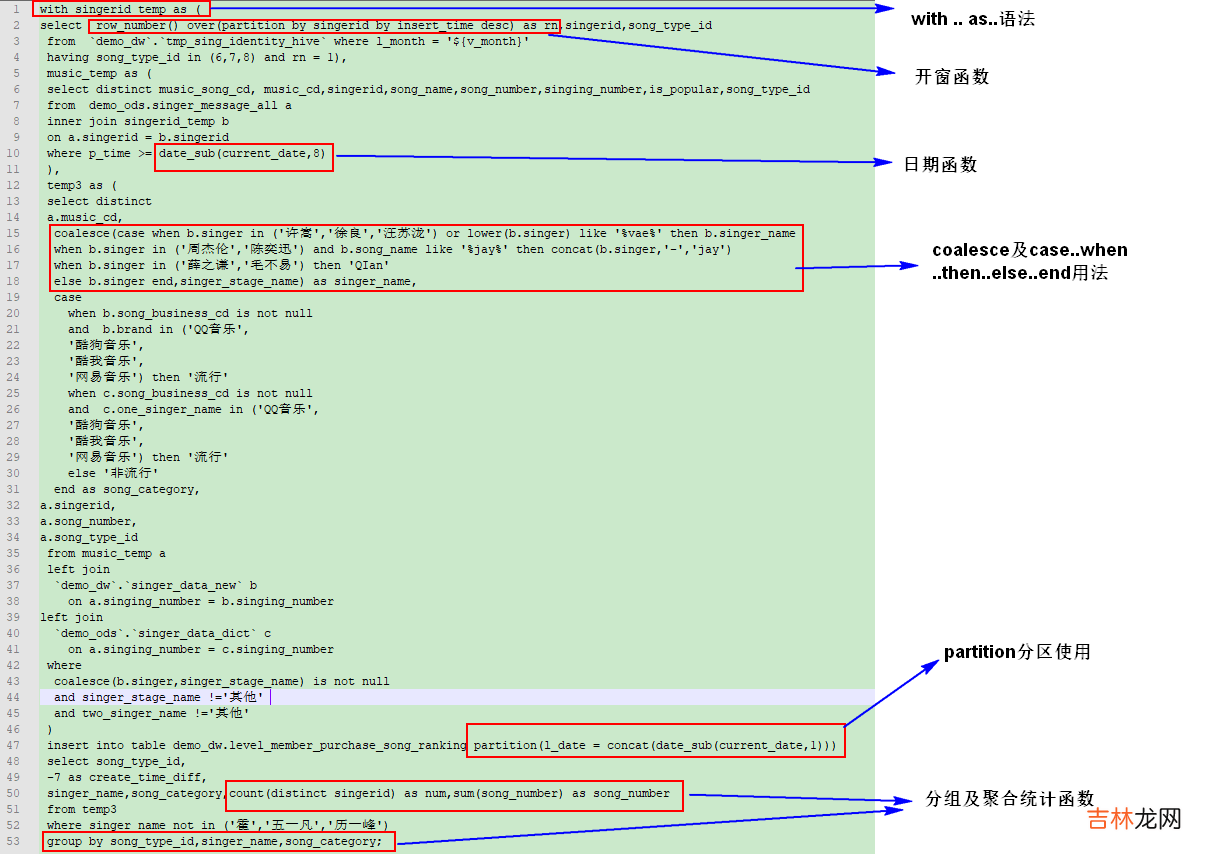
文章插图
这个是最近写的一条中等规模大小的SQL吧,只有50行左右而已,其他太长的也不好截屏,里面就用到了一些前面讲述的SQL语法,当然,这个SQL的业务场景需求我就不再赘述了,因为原本的SQL已经被我大批量的用新随便定义的表名和字段给替换了,目前已经面目全非了,毕竟不能暴露公司的一些业务的东西吧,之所以粘出来还是想实际的介绍下我前面那14条是怎样的结合着嵌入到一个SQL中的,随便看看就好,不需要深究其意思 。
2.Presto/Spark/Mapreduce 计算引擎对比? 平时一直使用大数据平台进行一些数据的处理,在执行查询语句时,是可以选择使用Presto,Spark,MapReduce不同的计算引擎进行工作,坦白讲,初次接触时也没搞明白它们的区别是什么,只知道有些SQL放在Presto引擎上执行准报错,但是放在Spark上就不会报错,它们的语法还是有差异的,presto没有spark内嵌的函数多 。据数据前辈给交接介绍时,大致就说,如果是单表查询,查询一些单表的数据量,聚合分组诸类,就使用Presto,相对来讲是比较快的;但是要同时使用到多个大数据表查询,那就使用Spark和MR是比较快些的;另外,Spark和MR相比,Spark运算速度应该有一些优势,但是遇到了特别特别大的计算量级时,资源再不够用,那么可能就会发生一些job abort,time out等比较让人牙疼的报错,毕竟这些报错不是由于SQL本身的编写出现的问题,而是和资源不够用相关,而且往往出现这个问题都是发生在SQL运行很久之后,记着我刚接手大数据没一个月时,曾经写了一条SQL执行了三个小时,最后给我了报了个time out,气得我没把键盘摔了!反过来看,使用MR的话好像很少会发生以上陈述问题,它可能会慢些,但它最后一定会不辱使命帮你执行完毕 。
2.1 Presto? Presto我讲不了特别深,毕竟我平时对于它的使用也仅仅是选择了这个引擎,然后执行了我写下的单表执行的SQL,不过有一点可以确定,他对你填写的类型的要求是苛刻的,比如假设你定义了一个字段叫做user_id,给定的它的类型为string(不是误写,在hive中就是定义为string,你可以理解为mysql中的varchar类型),于是你写了一条SQL:select * from demo_db.demo_user where user_id = 1001,那么它对于presto引擎执行那将会报错的,因为他检查语法时会发现你输入的1001是个整型数值,和string类型不匹配,但是对于Spark引擎执行时就不会出这个问题,我觉得Spark底层应该是对1001做了转化,将这个整型数值1001转化为了字符串‘1001’,故可以去做正常的查询 。下面我将整理几条关于Presto的介绍吧放在这里,也是我从各类网站中了解来的,可能对实际开发用处不大,但起码我们知道自己用了个什么计算引擎吧 。
- Presto是一个facebook开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节
- Presto是一款内存计算型的引擎,所以对于内存管理必须做到精细,才能保证query有序、顺利的执行,部分发生饿死、死锁等情况 。也正是因为它是基于内存计算的,它的速度也是很快的 。
- Presto采用典型的master-slave模型,master主要负责对从节点的一些管理以及query的解析和调度,而slave则是负责一些计算和读写 。
? 平时使用最多的还是SparkSql,用于一些查询,或者是搭建一些定时Job,使用SparkSql组件去完成对数据的抽取、转换、加载,但是查阅了相关介绍,Spark的应用远远不止这些,它还有一些流计算、机器学习、图计算的场景应用,下面有一段关于Spark应用场景介绍,是从
经验总结扩展阅读













- JAVA的File对象
- 华为开发者大会HDC2022:HMS Core 持续创新,与开发者共创美好数智生活
- Java 超新星开源项目 Solon v1.10.10 发布
- 将java装进u盘指南
- Java函数式编程:三、流与函数式编程
- 华为开发者大会2022:HMS Core 3D建模服务再升级,万物皆可驱动
- 2022,一个Java程序猿的外设配置
- 2022,一个Java程序猿的装机配置
- Java 多线程写zip文件遇到的错误 write beyond end of stream!
- 1 JAVA语言学习-面向对象