<https://help.aliyun.com/document_detail/441938.html>中看来了,我就不用我笨拙的语言来编排了,放在下面供大家探讨一下:
- 离线ETL
离线ETL主要应用于数据仓库,对大规模的数据进行抽取(Extract)、转换(Transform)和加载(Load),其特点是数据量大,耗时较长,通常设置为定时任务执行 。
- 在线数据分析(OLAP)
在线数据分析主要应用于BI(Business Intelligence) 。分析人员交互式地提交查询作业,Spark可以快速地返回结果 。除了Spark,常见的OLAP引擎包括Presto和Impala等 。Spark 3.0的主要特性在EMR中的Spark 2.4版本已支持,更多特性详情请参见Spark SQL Guide 。
- 流计算
流计算主要应用于实时大屏、实时风控、实时推荐和实时报警监控等 。流计算主要包括Spark Streaming和Flink引擎,Spark Streaming提供DStream和Structured Streaming两种接口,Structured Streaming和Dataframe用法类似,门槛较低 。Flink适合低延迟场景,而Spark Streaming更适合高吞吐的场景,详情请参见Structured Streaming Programming Guide 。
- 机器学习
Spark的MLlib提供了较丰富的机器学习库,包括分类、回归、协同过滤、聚合,同时提供了模型选择、自动调参和交叉验证等工具来提高生产力 。MLlib主要支持非深度学习的算法模块,详情请参见Machine Learning Library (MLlib) Guide 。
- 图计算
Spark的GraphX支持图计算的库,支持丰富的图计算的算子,包括属性算子、结构算子、Join算子和邻居聚合等 。详情请参见GraphX Programming Guide 。
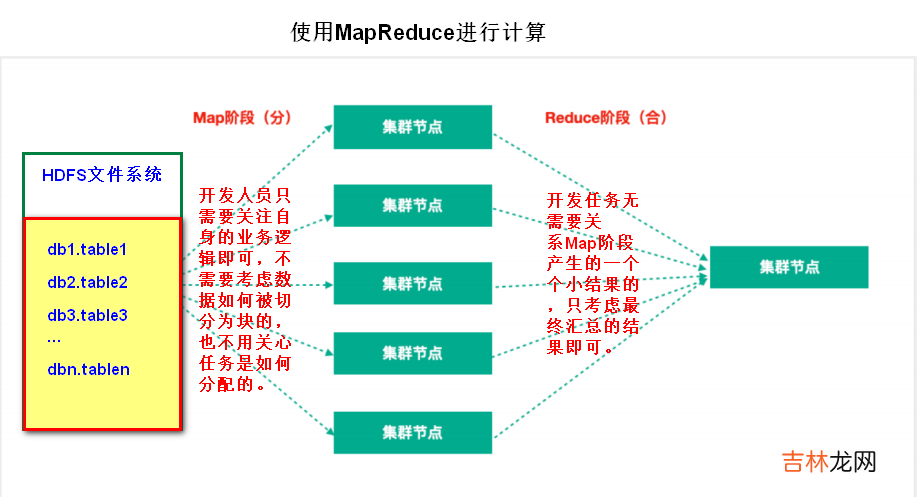
- Map阶段:Map阶段的主要作用是“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理 。Map阶段的这些任务可以并行计算,彼此间没有依赖关系 。
- Reduce阶段:Reduce阶段的主要作用是“合”,即对map阶段的结果进行全局汇总 。
文章插图
3.由数据同步想到的? 所谓大数据,必然和形形色色的数据表打交道,但是要清楚一点,对于一个规模还算可以的企业来讲,那下面的项目组肯定是一片一片的,他们之间的数据没有办法做到百分之百的共享,有时你想要的去做一些数据的分析,可能就需要其他项目组甚至第三方企业的支持,从别的渠道去拿到数据进行使用,因此,数据同步接入变成了大数据开发中必不可少的工作 。
? 其实数据同步接入的方式有很多,如果有数据库的权限,可以直接使用大数据平台自带的同步组件,编写一定的规则,配置好接入的频率,将数据接入过来;如果是第三方外部企业的数据,为了安全起见,我们通常也会选择接口的方式进行数据的接入,再同步至大数据平台;当然,使用消息中间件也是很不错的方式,比如Kafka,但是这东西总归有些严格意义上的限制,很多企业为了安全是不会对外暴露自身的Kafka服务地址的;还有一些数据量过大的情况,可以考虑sftp服务器的方式,直接将数据上传到指定的服务器的文件夹里,不过这个总归有些依赖于手工支持的弊端在里面,不过据说好像也可以编写脚本完成自动化的上传和拉取,对于我这个搞Java的来讲,这方面的解决策略还是不太懂的;其他方法也可以使用DolphinScheduler(DS)里面的一些小组件,去执行一些脚本来完成同步,当然脚本的编写就类似于
经验总结扩展阅读













- JAVA的File对象
- 华为开发者大会HDC2022:HMS Core 持续创新,与开发者共创美好数智生活
- Java 超新星开源项目 Solon v1.10.10 发布
- 将java装进u盘指南
- Java函数式编程:三、流与函数式编程
- 华为开发者大会2022:HMS Core 3D建模服务再升级,万物皆可驱动
- 2022,一个Java程序猿的外设配置
- 2022,一个Java程序猿的装机配置
- Java 多线程写zip文件遇到的错误 write beyond end of stream!
- 1 JAVA语言学习-面向对象