motivationActive Learning 存在的重要问题:现实数据极度不平衡,有许多类别很少见(rare),又有很多类别是冗余的(redundancy),又有些数据是 OOD 的(out-of-distribution) 。
1. 不同的次模函数提出三种次模函数的变体:
- 次模条件增长(Submodular Conditional Gain, SCG),越大说明差异越大:
- 次模交互信息(Submodular Mutual Information, SMI),越大说明相似性越大:
- 次模条件交互信息(Submodular Conditional Mutual Information, SCMI),上面二者的结合:
其中 SCMI 可以通过设置不同的 $\mathcal{Q}$ 和 $\mathcal{P}$ 得到另外两种次模函数(算上标准次模函数的话就是三种),对应关系和适用场景如下:

文章插图
图 1 各种SIM 函数
2. 次模函数的实例化问题次模信息度量(submodular information measures, SIM),一般有三种实例化的问题:
- 设施选址问题(Facility Location)
- 图切问题(Graph Cut)
- 对数行列式问题(Log Determinant)
2. 样本不平衡主要指某些类别出现很少的情况,例如医疗影像病灶判断,真正 positive 的数据是很少的,因此可以使用 SMI 次模函数(图 1 第二行),在保证多样性的基础上,使得 AL 检索的样本与 $\mathcal{Q}$(有病灶的影像)尽可能接近 。
3. 样本冗余虽然次模函数本身保证了多样性,但是在 batch active learning 中,多样性的保证指存在与一个 batch 中 。因此可以使用 SCG 次模函数(图 1 第三行),提供额外的多样性正则信息 。
4. OOD 数据未标注的数据容易出现 OOD 的数据,例如在手写数字识别的任务中,未标注的数据集中出现了手写字母的图片(不是任务目标也无法提供有效信息),是应当避免的 。因此可以使用 SCMI 次模函数(图 1 第四行),使得 AL 检索的样本与 in-domin 的数据尽可能相似,与 out-of-domin 的数据尽可能远离,同时保证多样性 。
5. 混合场景当未标注数据出现了多种情景时也可以进行组合(例如即出现了冗余的数据,也出现了 OOD 的数据):
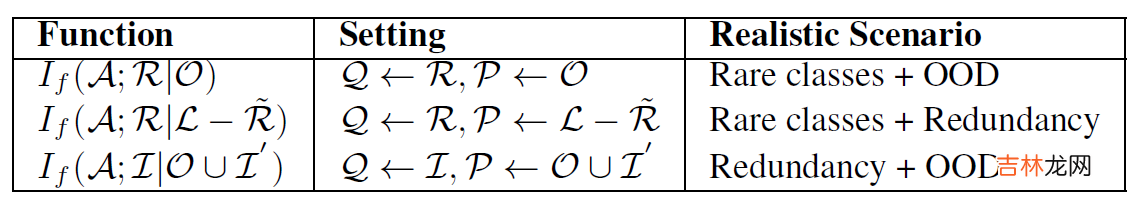
文章插图
图 2 混合场景
同时,类似于在线学习(online learning),未标注的数据集有可能是在不断产生中的,因此一开始数据集未出现上述场景的时候可以使用标准次模函数,出现了上述场景之后(例如某次数据收集之后出现了大量 OOD 样本)了可以再改用 SIM 的变体 。
【论文笔记 - SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios】
经验总结扩展阅读
















- JVM学习笔记——类加载和字节码技术篇
- Agda学习笔记1
- 萌新版 xss学习笔记
- MyBatis笔记03------XXXMapper.xml文件解析
- 我的Spark学习笔记
- 7000-8000高性价比笔记本排行榜2022-7000-8000值得买的笔记本排行榜
- JVM学习笔记——垃圾回收篇
- 黑莓q5用安装微信的方法a 用黑莓自带的印象笔记手敲的 看不懂的宝宝们在私聊我吧
- JVM学习笔记——内存结构篇
- 【lwip】08-ARP协议一图笔记及源码实现