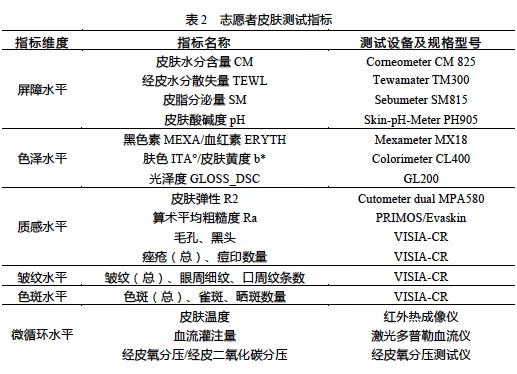
文章图片

文章图片
(二)数据处理方法
01描述性统计
描述性分析是社会调查统计分析的第一个步骤 , 对调查所得的大量数据资料进行初步的整理和归纳 , 以找出这些资料的内在规律 , 包括集中趋势和分散趋势 。 主要借助各种数据所表示的统计量 , 如均数、百分比等 , 进行单因素分析 。
02差异性分析
差异性分析是常用的数据分析方法 , 用于检测科学实验中实验组与对照组之间是否有差异 , 以及差异是否显著的办法 。 作为判断两个或是多个数据集之间是否存在差异的方法 , 差异显著性检验一直被广泛应用于各个科研领域 , 其原理是基于比较均值 , 即比较不同组别的均值 , 从而得出组间差异 。
03偏相关分析
偏相关分析是指当两个变量同时与第三个变量相关时 , 将第三个变量的影响剔除 , 只分析另外两个变量之间相关程度的过程 。 显著性P值是针对原假设H0(假设两变量无线性相关)而言的 , 一般假设检验的显著性水平为0.05 。 若P值小于0.05则拒绝原假设H0 , 说明两变量有线性相关的关系;若P值大于0.05 , 则一般认为无线性相关关系 。 判定标准为相关系数R值 , R值越大说明相关程度越高;反之则相关程度越低 。
04相关性分析
相关性分析是指对两个或多个具备相关性的变量元素进行分析 , 从而衡量两个变量因素的相关密切程度 。 相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析 。 相关性系数的计算过程可表示为:将每个变量都转化为标准单位 , 乘积的平均数即为相关系数 。 两个变量的关系可以直观地用散点图表示 , 当其紧密地群聚于一条直线的周围时 , 变量间存在强相关性 。
(三)研究结果与讨论
01不同肤色类型分布统计
(1)总体分布
基于ITA°分型方法 , 将5000名中国女性志愿者肤色由浅至深分为Ⅰ(非常浅)、Ⅱ(浅)、Ⅲ(中度)、Ⅳ(棕褐)型 , 所有志愿者的ITA°范围为17.17°~69.17° 。 不同肤色类型的分布如下:Ⅱ型(2740)>Ⅰ型(1270)>Ⅲ型(920)>Ⅳ型(70)(图2A) 。 结果表明 , 中国女性志愿者肤色整体较浅 , 超过一半的受试者肤色为Ⅱ型 , 没有观察到Ⅴ型、Ⅵ型较黑皮肤 。
(2)年龄分布
各肤色类型的年龄分布为A1年龄段(18-29):Ⅱ型(1430)>Ⅰ型(820)>Ⅲ型(250)(图2B);A2年龄段(30-45):Ⅱ型(1310)>Ⅲ型(670)>Ⅰ型(450)>Ⅳ型(70)(图2C) 。 结果表明 , A1年龄段志愿者肤色整体较浅 , 无Ⅳ型肤色;A2年龄段志愿者相比A1肤色较深 , 且Ⅰ型肤色志愿者人数显著较少 , IV型肤色志愿者人数显著较多 。 随年龄增长 , Ⅰ型、Ⅱ型肤色志愿者人数逐渐减少 , Ⅲ型、Ⅳ型肤色志愿者人数显著增多 。
(3)地域分布
横向来看 , 各肤色类型的地域分布为北京:Ⅱ型(540)>Ⅰ型(410)>Ⅲ型(40)>Ⅳ型(10);广州:Ⅱ型(550)>Ⅲ型(370)>Ⅰ型(40)=Ⅳ型(40);上海:Ⅱ型(720)>Ⅲ型(240)>Ⅰ型(30)>Ⅳ型(10);武汉:Ⅱ型(520)>Ⅲ型(250)>Ⅰ型(220)>Ⅳ型(10);成都:Ⅰ型(570)>Ⅱ型(410)>Ⅲ型(20)(图2D) 。 结果表明 , 成都志愿者肤色整体最浅 , 无Ⅳ型肤色;北京志愿者肤色整体较浅;上海、武汉志愿者肤色较深;广州志愿者肤色最深 。 纵向来看 , 各肤色类型的地域分布为Ⅰ型:成都(570)>北京(410)>武汉(220)>广州(40)>上海(30) , Ⅱ型:上海(720)>广州(550)>北京(540)>武汉(520)>成都(410) , Ⅲ型:广州(370)>武汉(250)>上海(240)>北京(40)>成都(20)Ⅳ型:广州(40)>北京(10)=武汉(10)=上海(10)>成都(0)(图2D) 。 肤色最浅的Ⅰ型肤色人群普遍分布于成都和北京 , 广州、上海分布较少;Ⅱ型肤色人群分布较为平均;Ⅲ型肤色人群较多分布于广州 , 北京、成都分布较少;Ⅳ型肤色人群较多分布于广州 , 成都未观察到Ⅳ型肤色人群 。
经验总结扩展阅读


















- 分析面部美学分析一下,为何一些演员扮演古装会变丑
- 发型 东方神起昌珉早期造型太冲击!海胆发型引前辈露出意味深长的笑容
- 活动网店高成交率高的逻辑揭露:产品图作用+分析
- 品牌传承东方韵味 姬存希掀起时尚新风潮
- 分析安徽美术艺考:校考遇到色彩头像想要拿高分,学会从这几个角度分析!
- 泰妆 彩妆师分析「五官量感」适合妆容风格,找出你的完美妆容
- 分析彻底清洁毛孔的10个明智做法
- 底妆 彩妆师分析「五官量感」适合妆容风格,找出你的完美妆容
- 分析彩妆师分析「五官量感」适合妆容风格,找出你的完美妆容
- 分析韩国魅力女神朴信惠,她的颜值到底有多高?