论文信息
论文标题:Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks论文作者:Jiaying Wu、Bryan Hooi论文来源:2022, arXiv论文地址:download 论文代码:downloadAbstract开源的数据集存在虚假相关性 , 这种虚假相关性来自三个方面:
- event-based data collection and labeling schemes assign the same veracity label to multiple highly similar posts from the same underlying event;
- merging multiple data sources spuriously relates source identities to veracity labels;
- labeling bias;
1 Introduction现有数据集的构建过程中存在虚假的 属性-标签相关性 。回顾基于事件的数据集采集框架 , 首先对事实有价值的事件自动检测 , 然后剔除大量包含相同事件关键词高度相似的微博 。此外 , 一些基准数据集还通过合并现有多个源的数据样本 , 来平衡类分布 。
忽略虚假信息会导致不公平的过度预测 , 从而限制了模型的泛化和适应性 。在情绪分类、参数推理理解 和 事实验证 等一些自然语言处理任务中也发现了类似的问题 , 但社交媒体谣言检测的任务仍未得到充分的探索 。
2 Spurious Correlations in Event-Based Datasets2.1 Event-Based Data CollectionNewsworthy Event Selection
从具有权威的事实核查网络收集事件 , 或由专业人士确定候选事件 。
Keyword-Based Microblog Retrieval
现有的数据集通常是基于事件的自动数据收集策略 , 即对每个事件:
- 从其 claim 中提取关键词;
- 通过基于关键词的搜索获取微博;
- 选择有影响力的微博;
【PSA 谣言检测——《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》】Microblog Labeling Scheme
Event-level labeling assigns all source posts under an event with the same event-level factchecking label.
Post-level labeling annotates every source post independently.
2.2 Possible Causes of Spurious CorrelationsIntra-Event Textual Similarity在每个 Event 下 , 基于自动关键字的微博检索框架收集了大量具有相同标签的高度相似的关键词共享样本 , 甚至获得了相同的微博文本(Fig.1) 。因此 , 事件关键字和类标签之间的相关性导致强文本线索 , 难以概括当前 Event。

文章插图
根据现有工程所采用的 post-level data splitting scheme , 也就是使用关键词相关性对帖子进行收集 。
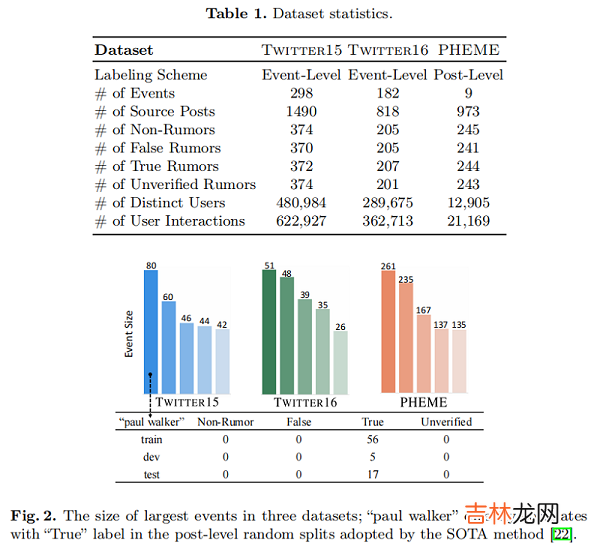
文章插图
具体来说 , 前 5 个最大的事件覆盖了 PHEME 中 96.09% 的数据样本 , 而大型事件(包含超过5个关键词共享推文)覆盖了 Twitter 15 和 Twitter16 中超过70% 的样本 。大的事件规模导致特定事件的 keyword-label 相关性的流行 , 进一步加剧了问题 。
Merge of Data Sources为了平衡标签 , Twitter 15 和 Twitter16 合并了来自包括[4,12,16] 在内的多个来源的推文 , 并从经过验证的媒体账户中提取其他新闻事件 。虽然不同的数据源所覆盖的事件不重叠 , 但数据源和标签之间的直接相关性可能会导致数据源特征和标签之间的虚假相关性 。
经验总结扩展阅读
















- 基因检测有必要吗
- GACL 谣言检测《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
- ipsa属于什么档次?
- 非典为什么只感染华人?
- 吃鸡怎么举报100让对方被检测?
- 水质检测到哪里
- 安检门能检测什么东西
- 口罩如何检测是否合格
- 标致308电脑检测口在哪里?
- 比亚迪s6检测不到钥匙怎么办?