PSA 谣言检测——《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》( 二 )
如 Fig 3 所示 , 来自每个源的推文的 user interaction count(评论和转发)和 interaction time range of tweets 形成了不同的模式 。例如 , 所有来自 PLOS_ONE 的推文都是“True” , 传播得很快 , 往往会引起更少的互动 。这些特定于源的传播模式可能被基于图或时间的模型所利用 。

文章插图
Labeling Bias
由于文本内容相似 , 简单的为其自动设置相同标签 , 会带来严重的标签偏差 , 举例如 Fig.4 所示:

文章插图
3 Event-Separated Rumor Detection3.1 Problem Formulation

文章插图
现有的方法大多忽略了底层的 microblog-event 关系 , 采用了 event-mixed post-level data splits , 导致 $\mathcal{E}_{t r}$ 和 $\mathcal{E}_{t e}$ 之间存在显著的重叠 。然而 , 在实践中 , 测试数据的先验知识并不总是得到保证(例如 , 模型从训练和测试数据中重复推文获得的性能收益不太可能推广) , 而以前的假设可能导致事件内文本相似性导致的性能高估 。
为了消除这些混杂的事件特异性相关性 , 本文建议研究一个更实际的问题 , 即 event-separated rumor detection , 其中 $\mathcal{E}_{t r} \cap \mathcal{E}_{t e}=\varnothing$ 。由于潜在的事件分布转移 , 这项任务具有挑战性 , 因此它提供了一种评估去偏谣言检测性能的方法 。
3.2 Existing ApproachesPropagation-Based
(1) TD-RvNN(2) GLAN(3) BiGCN(4) SMAN
Content-Based
(1) BERT(2) XLNet(3) RoBERTa(4) DistilBERT
Data Splitting
对于所有三个数据集 , 我们抽取 10% 的实例进行验证 , 然后将剩下的 3:1 分成训练集和测试集 。具体来说 , 分别根据 Twitter15、Twitter16、PHEME 上发布的公开事件 id 获得了事件分离分割 。
3.3 SOTA Models’Performance is Heavily OverestimatedFig.5 显示了事件混合和事件分离的谣言检测性能之间的鲜明对比 。此外 , 尽管在所有三个数据集上具有最佳事件分离性能的一致性 , 但所有模型在 Twitter 15 和 Twitter16 上实现的事件混合性能都显著高于 PHEME , 前者采用事件级标记 , 后者采用后级标记(见第1.1节) 。这一差距与我们的假设相一致 , 即直接的event-label 相关性会导致额外的偏差 。

文章插图
结果表明 , 现有的方法严重依赖于虚假的事件特异性相关性 。尽管在事件混合设置下表现良好 , 但这些模型不能推广到看不见的事件 , 导致现实世界的适应性较差 。
4 Proposed Method为了解决事件分离谣言检测的挑战 , 我们提出了 Publisher Style Aggregation(PSA) , 这是一种新的方法 , 可以根据每个出版商的聚合帖子来学习可推广的 publisher 特征 , 如 Fig.6 所示 。
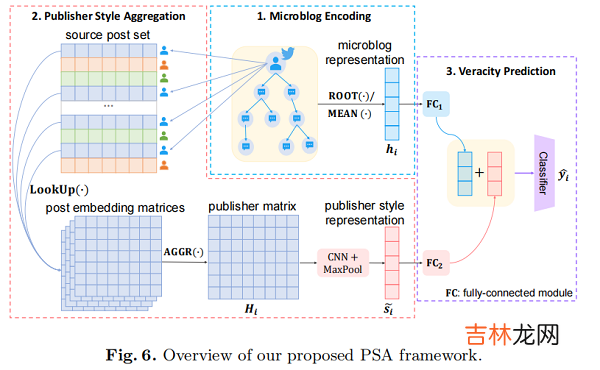
文章插图
4.1 Consistency of Publisher Style源帖子发布者是非常有影响力的用户 。每个发布者独特的可信度立场和写作风格可以表现出独特的特征 , 这有助于决定他们的帖子的真实性 。为了获得更直观的观点 , 我们在 Fig.7 中说明了Twitter15 发布者对每个类的倾向 。
经验总结扩展阅读












- 基因检测有必要吗
- GACL 谣言检测《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
- ipsa属于什么档次?
- 非典为什么只感染华人?
- 吃鸡怎么举报100让对方被检测?
- 水质检测到哪里
- 安检门能检测什么东西
- 口罩如何检测是否合格
- 标致308电脑检测口在哪里?
- 比亚迪s6检测不到钥匙怎么办?