@
目录
- 底层原理
- Master架构
- RegionServer架构
- Region/Store/StoreFile/Hfile之间的关系
- 写流程
- 写缓存刷写
- 读流程
- 文件合并
- 分区
- JAVA API编程
- 准备
- 示例
文章插图
- Meta 表格介绍:全称 hbase:meta,只是在 list 命令中被过滤掉了,本质上和 HBase 的其他表格一样,不要去改这个表 。
- RowKey:([table],[region start key],[region id]) 即 表名,region 起始位置和 regionID 。
- 列:
- info:regioninfo 为 region 信息,存储一个 HRegionInfo 对象 。
- info:server 当前 region 所处的 RegionServer 信息,包含端口号 。
- info:serverstartcode 当前 region 被分到 RegionServer 的起始时间 。
- 如果一个表处于切分的过程中,即 region 切分,还会多出两列 info:splitA 和 info:splitB,存储值也是 HRegionInfo 对象,拆分结束后,删除这两列 。
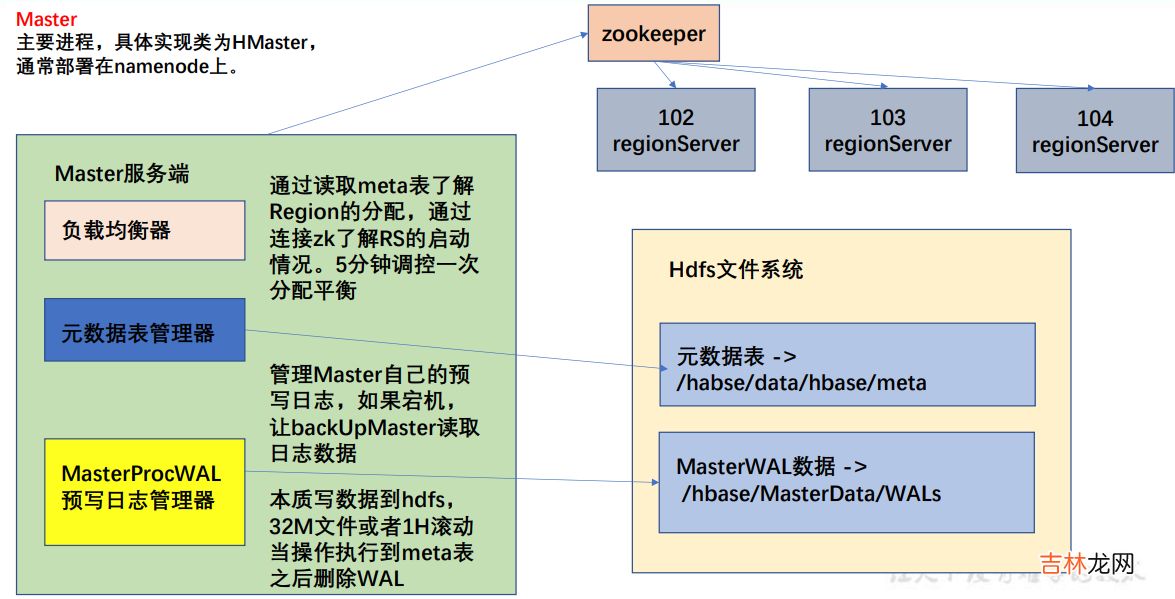
- 注意:在客户端对元数据进行操作的时候才会连接 master,如果对数据进行读写,直接连接zookeeper 读取目录/hbase/meta-region-server 节点信息,会记录 meta 表格的位置 。直接读取即可,不需要访问 master,这样可以减轻 master 的压力,相当于 master 专注 meta 表的写操作,客户端可直接读取 meta 表 。
- 在 HBase 的 2.3 版本更新了一种新模式:Master Registry 。客户端可以访问 master 来读取meta 表信息 。加大了 master 的压力,减轻了 zookeeper 的压力 。
- HMaster通常部署在NameNode上,HMaster中主要有负载均衡器,元数据表管理器,预写日志管理器(MasterProcWAL) 。
文章插图
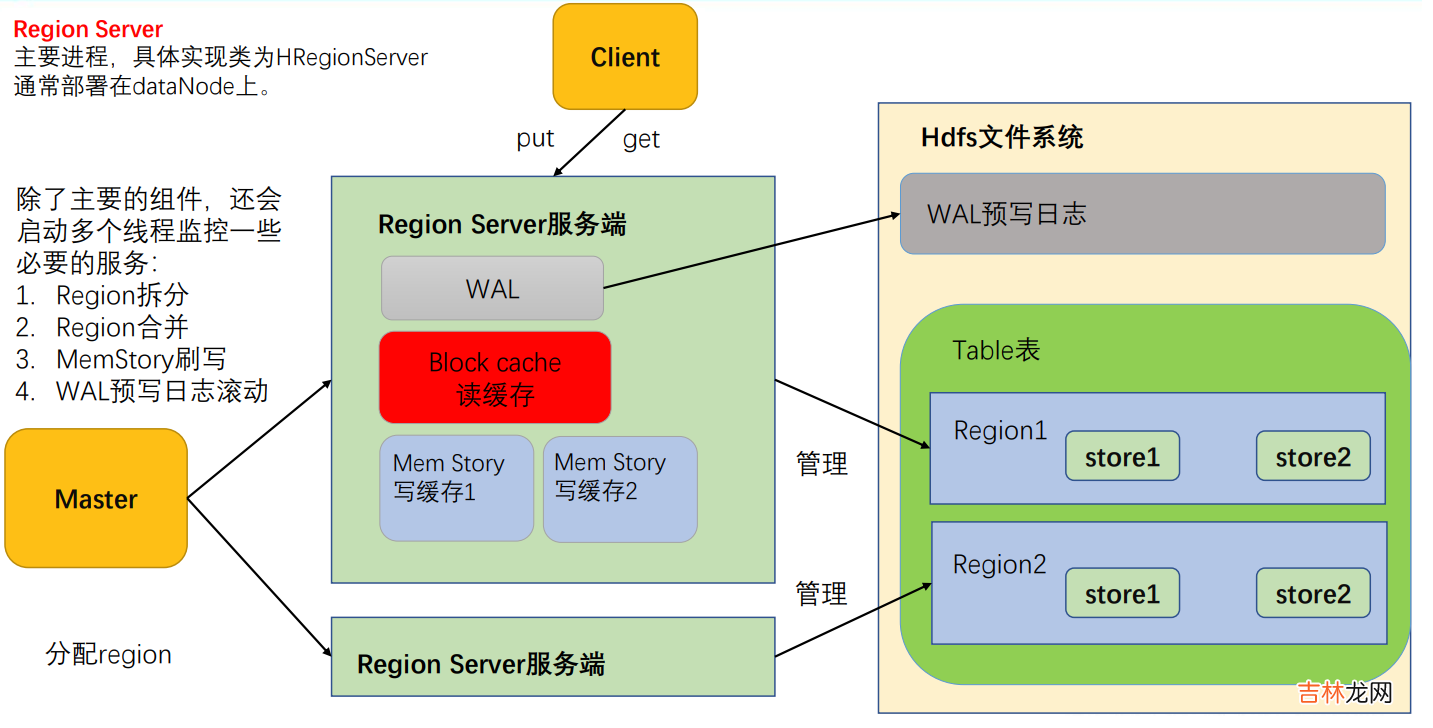
- MemStore:写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile,写入到对应的文件夹 store 中 。
- WAL:由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中 。所以在系统出现故障的时候,数据可以通过这个日志文件重建 。
- BlockCache:读缓存,每次查询出的数据会缓存在 BlockCache 中,方便下次查询 。
文章插图
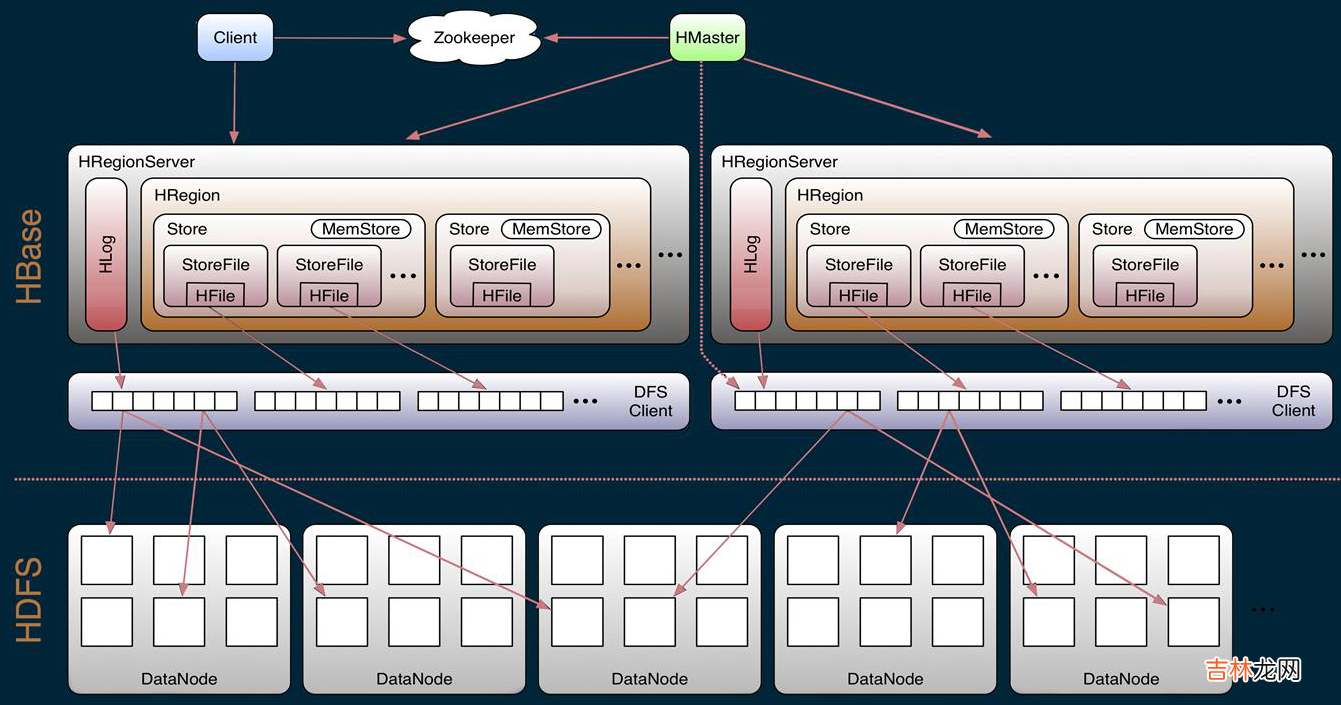
- Region
- table在行的方向上分隔为多个Region 。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上 。
- Region按大小分隔,表中每一行只能属于一个region 。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region 。
- Store
- 每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store) 。一个Store由一个memStore和0或多个StoreFile组成 。
- HBase以store的大小来判断是否需要切分region 。
- MemStore
- memStore 是放在内存里的 。保存修改的数据即keyValues 。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照 。目前hbase 会有一个线程来负责memStore的flush操作 。
经验总结扩展阅读
- 电子信息工程专业和电子信息科学与技术专业有什么区别 哪个更好就业
- 生物技术专业和生物科学专业有什么区别 哪个更好就业
- 2023年10月17日适合大扫除吗 2023年10月17日大扫除好不好
- 五加三隔离政策是什么意思
- 2022大雪节气能回娘家吗
- 2023年12月7日大雪嫁娶好不好 适不适合操办婚嫁之事
- 大雪节气的诗句有哪些
- 大雪节气艾灸的好处是什么
- 2022大雪节气可以同房吗
- 属猴的2023年9月哪天结婚大吉大利
- memStore 是放在内存里的 。保存修改的数据即keyValues 。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照 。目前hbase 会有一个线程来负责memStore的flush操作 。














