读流程在了解读流程之前,需要先知道读取的数据,这就需要了解HFile ;HFile 是存储在 HDFS 上面每一个 store 文件夹下实际存储数据的文件 。里面存储多种内容 。包括数据本身(keyValue 键值对)、元数据记录、文件信息、数据索引、元数据索引和一个固定长度的尾部信息(记录文件的修改情况) 。键值对按照块大小(默认 64K)保存在文件中,数据索引按照块创建,块越多,索引越大 。每一个 HFile 还会维护一个布隆过滤器(就像是一个很大的地图,文件中每有一种 key,就在对应的位置标记,读取时可以大致判断要 get 的 key 是否存在 HFile 中) 。KeyValue 内容如下:
- rowlength -----------→ key 的长度
- row -----------------→ key 的值
- columnfamilylength --→ 列族长度
- columnfamily --------→ 列族
- columnqualifier -----→ 列名
- timestamp -----------→ 时间戳(默认系统时间)
- keytype -------------→ Put
文章插图
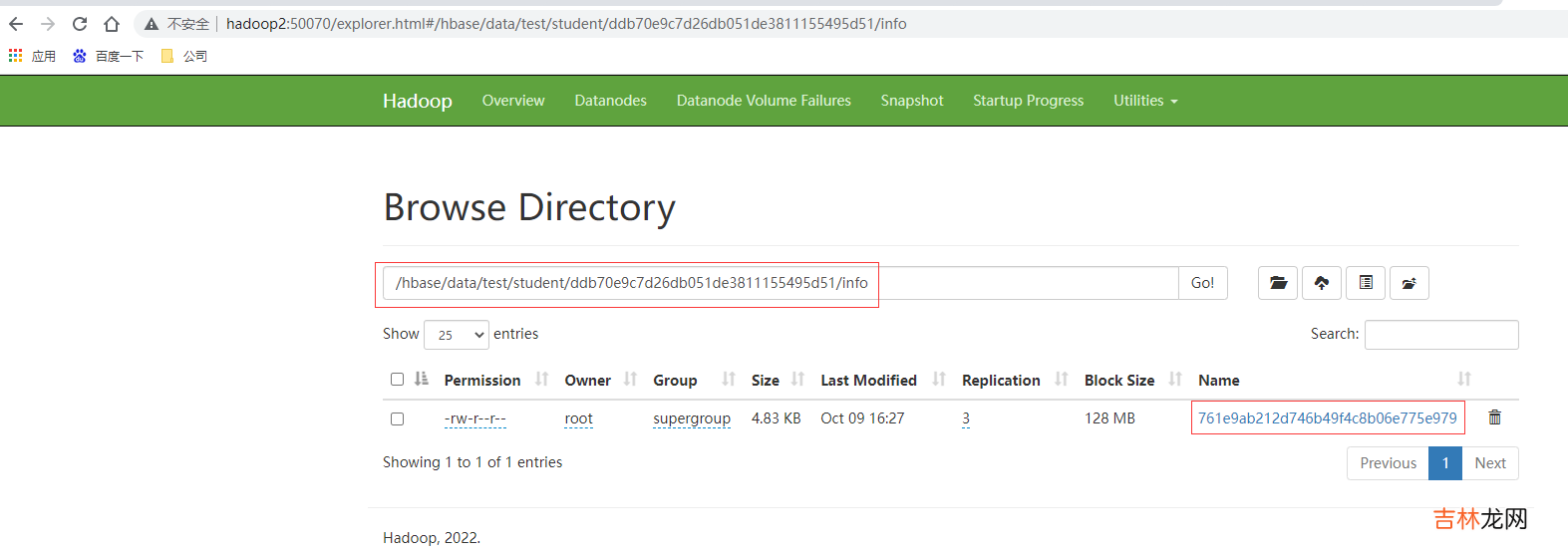
# hbase hfile -m -f /hbase/data/命名空间/表名/regionID/列族/HFile 名hbase hfile -m -f /hbase/data/test/student/ddb70e9c7d26db051de3811155495d51/info/761e9ab212d746b49f4c8b06e775e979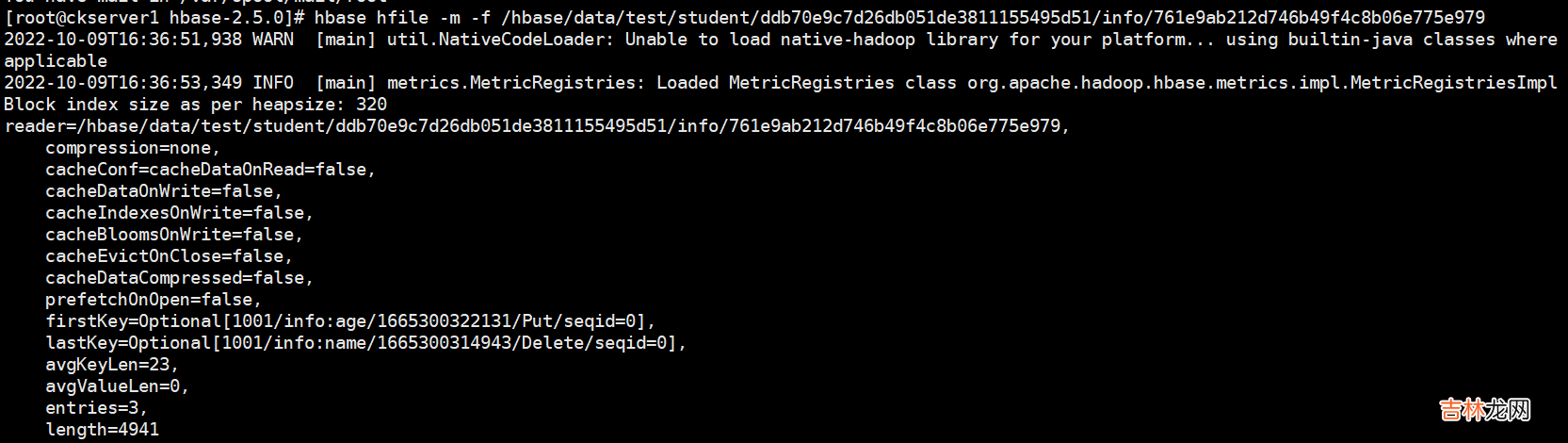
文章插图
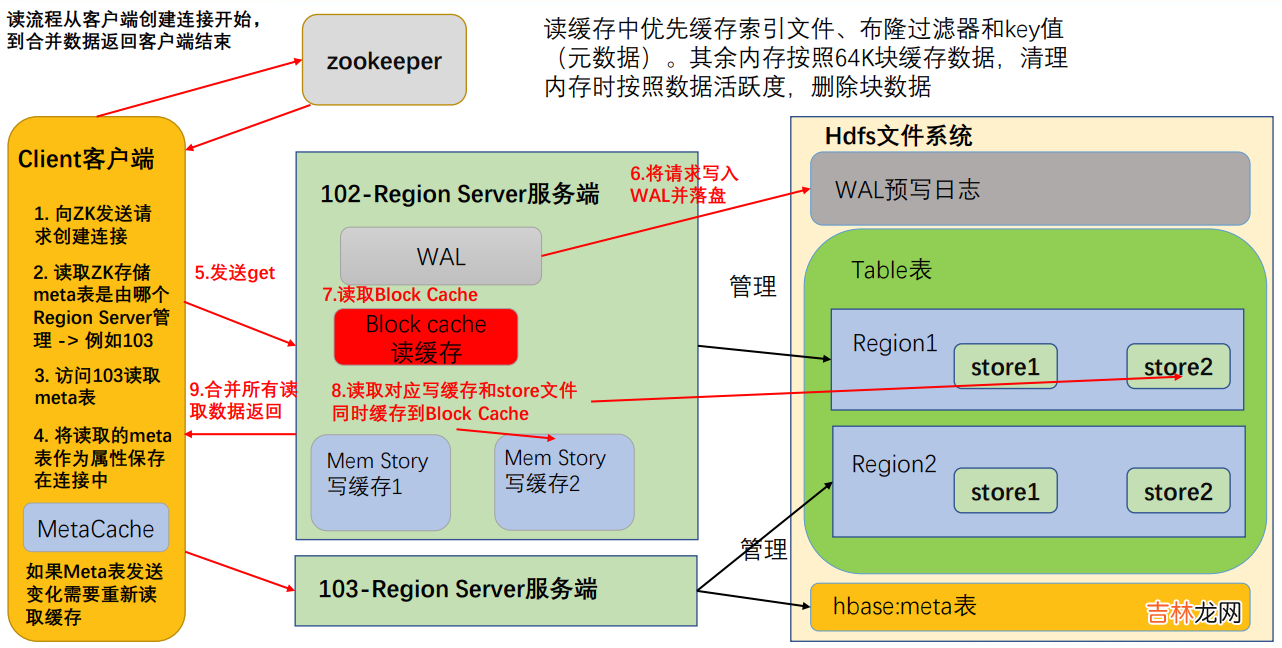
读流程如下
文章插图
- 首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢; 之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
- 创建 Table 对象发送 get 请求 。
- 优先访问 Block Cache,查找是否之前读取过,并且可以读取 HFile 的索引信息和布隆过滤器 。
- 不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和store 中的文件 。
- 最终将所有读取到的数据合并版本,按照 get 的要求返回即可 。
- HFile 带有索引文件,读取对应 RowKey 数据会比较快 。
- Block Cache 会缓存之前读取的内容和元数据信息,如果 HFile 没有发生变化(记录在 HFile 尾信息中),则不需要再次读取 。
- 使用布隆过滤器能够快速过滤当前 HFile 不存在需要读取的 RowKey,从而避免读取文件 。(布隆过滤器使用 HASH 算法,不是绝对准确的,出错会造成多扫描一个文件,对读取数据结果没有影响)
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction 。MinorCompaction会将临近的若干个较小的 HFile 合并成一个较大的 HFile,并清理掉部分过期和删除的数据,有系统使用一组参数自动控制,Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉所有过期和删除的数据,由参数 hbase.hregion.majorcompaction控制,默认 7 天 。
经验总结扩展阅读












- 电子信息工程专业和电子信息科学与技术专业有什么区别 哪个更好就业
- 生物技术专业和生物科学专业有什么区别 哪个更好就业
- 2023年10月17日适合大扫除吗 2023年10月17日大扫除好不好
- 五加三隔离政策是什么意思
- 2022大雪节气能回娘家吗
- 2023年12月7日大雪嫁娶好不好 适不适合操办婚嫁之事
- 大雪节气的诗句有哪些
- 大雪节气艾灸的好处是什么
- 2022大雪节气可以同房吗
- 属猴的2023年9月哪天结婚大吉大利