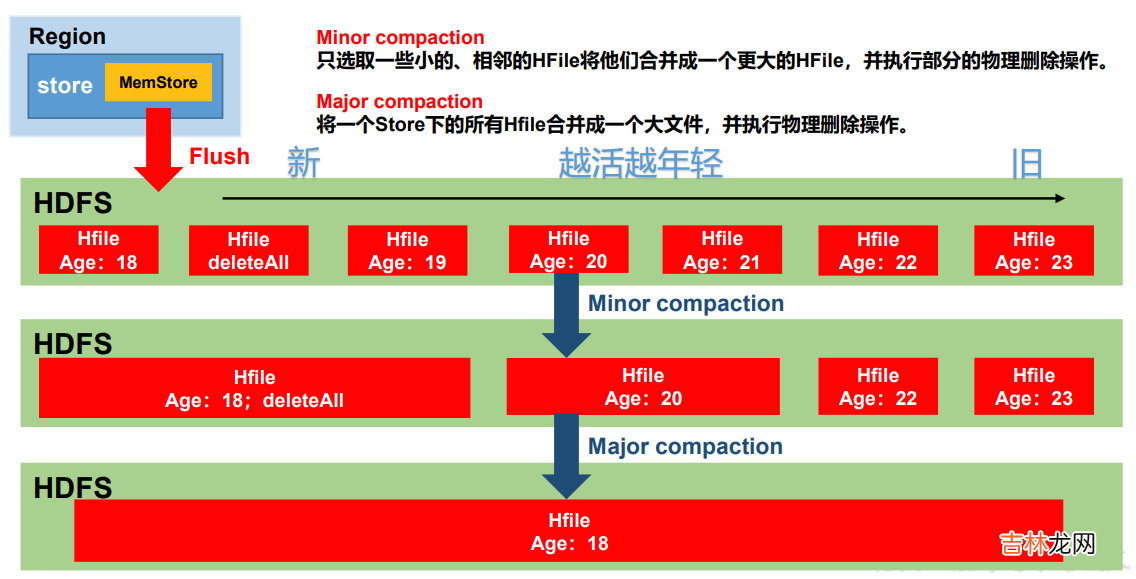
文章插图
- Minor Compaction 控制机制:参与到小合并的文件需要通过参数计算得到,有效的参数有 5 个
- hbase.hstore.compaction.ratio(默认 1.2F)合并文件选择算法中使用的比率 。
- hbase.hstore.compaction.min(默认 3) 为 Minor Compaction 的最少文件个数 。
- hbase.hstore.compaction.max(默认 10) 为 Minor Compaction 最大文件个数 。
- hbase.hstore.compaction.min.size(默认 128M)为单个 Hfile 文件大小最小值,小于这个数会被合并 。
- hbase.hstore.compaction.max.size(默认 Long.MAX_VALUE)为单个 Hfile 文件大小最大值,高于这个数不会被合并 。小合并机制为拉取整个 store 中的所有文件,做成一个集合 。之后按照从旧到新的顺序遍历 。
- 判断条件为:
- 过小合并,过大不合并 。
- 文件大小/ hbase.hstore.compaction.ratio < (剩余文件大小和) 则参与压缩 。所有把比值设置过大,如 10 会最终合并为 1 个特别大的文件,相反设置为 0.4,会最终产生 4 个 storeFile 。不建议修改默认值 。
- 满足压缩条件的文件个数达不到个数要求(3 <= count <= 10)则不压缩 。
- 自定义分区:每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个 region 维护的rowKey 范围,则该数据交给这个 region 维护 。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高 HBase 性能 。
# 手动设定预分区create 'student1','info', SPLITS => ['1000','2000','3000','4000']# 生成 16 进制序列预分区create 'student2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}# 按照文件中设置的规则预分区,创建 student-splits.txt 文件内容如下:aaaabbbbccccdddd# 然后执行:create 'student3', 'info',SPLITS_FILE => 'student-splits.txt'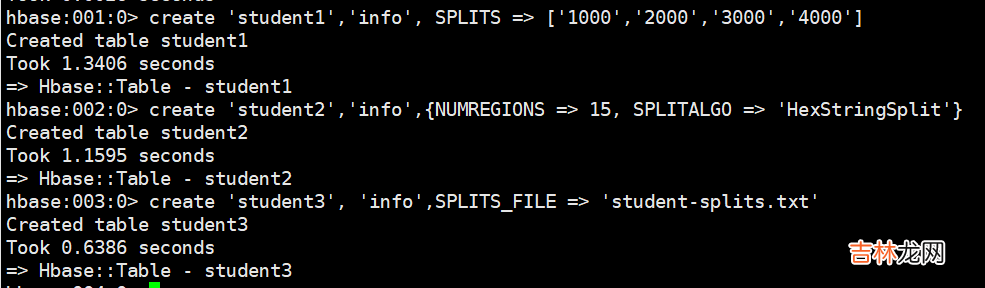
文章插图
- 系统拆分:Region 的拆分是由 HRegionServer 完成的,在操作之前需要通过 ZK 汇报 master,修改对应的 Meta 表信息添加两列 info:splitA 和 info:splitB 信息 。之后需要操作 HDFS 上面对应的文件,按照拆分后的 Region 范围进行标记区分,实际操作为创建文件引用,不会挪动数据 。刚完成拆分的时候,两个 Region 都由原先的 RegionServer 管理 。之后汇报给 Master,由Master将修改后的信息写入到Meta表中 。等待下一次触发负载均衡机制,才会修改Region的管理服务者,而数据要等到下一次压缩时,才会实际进行移动 。不管是否使用预分区,系统都会默认启动一套 Region 拆分规则 。
- 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过hbase.hregion.max.filesize (10G),该 Region 就会进行拆分 。0.94 版本之后,2.0 版本之前 => IncreasingToUpperBoundRegionSplitPolicy
- 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该 Region 就会进行拆分 。其中 initialSize 的默认值为 2 * hbase.hregion.memstore.flush.size,R 为当前 Region Server 中属于该 Table 的Region 个数(0.94 版本之后) 。具体的切分策略为:
- 第一次 split:1^3 * 256 = 256MB
- 第二次 split:2^3 * 256 = 2048MB
- 第三次 split:3^3 * 256 = 6912MB
- 第四次 split:4^3 * 256 = 16384MB > 10GB,因此取较小的值 10GB
- 后面每次 split 的 size 都是 10GB 了 。2.0 版本之后 => SteppingSplitPolicy
经验总结扩展阅读
- 电子信息工程专业和电子信息科学与技术专业有什么区别 哪个更好就业
- 生物技术专业和生物科学专业有什么区别 哪个更好就业
- 2023年10月17日适合大扫除吗 2023年10月17日大扫除好不好
- 五加三隔离政策是什么意思
- 2022大雪节气能回娘家吗
- 2023年12月7日大雪嫁娶好不好 适不适合操办婚嫁之事
- 大雪节气的诗句有哪些
- 大雪节气艾灸的好处是什么
- 2022大雪节气可以同房吗
- 属猴的2023年9月哪天结婚大吉大利















