- memStore内存中的数据写到文件后就是StoreFile(即memstore的每次flush操作都会生成一个新的StoreFile),StoreFile底层是以HFile的格式保存 。
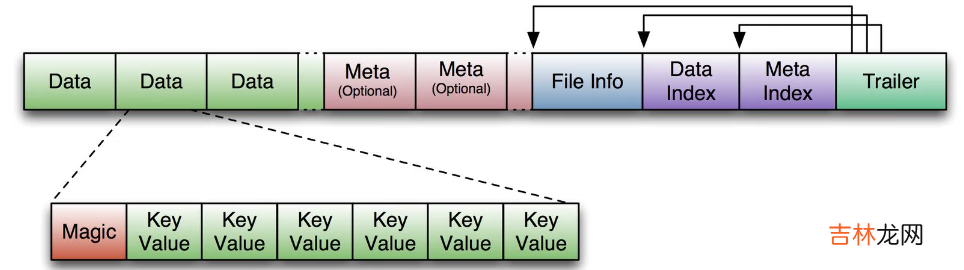
- HFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件 。一个StoreFile对应着一个HFile 。而HFile是存储在HDFS之上的 。HFile文件格式是基于Google Bigtable中的SSTable,如下图所示:
文章插图
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo 。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息 。
写流程
文章插图
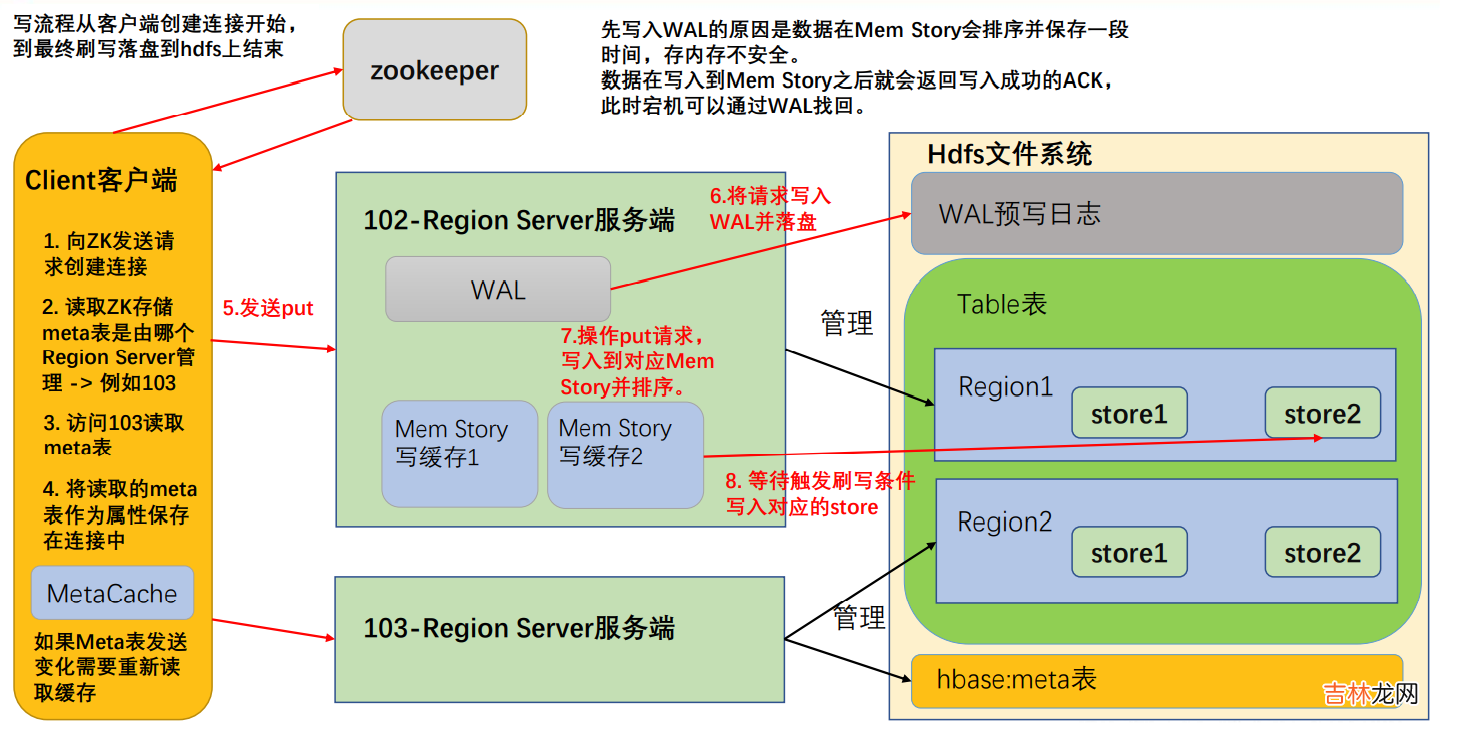
- 首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢; 之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
- 调用Table的put方法写入数据,此时还需要解析RowKey,对照缓存的MetaCache,查看具体写入的位置有哪个 RegionServer;
- 将数据顺序写入(追加)到 WAL,此处写入是直接落盘的,并设置专门的线程控制 WAL 预写日志的滚动(类似 Flume);
- 根据写入命令的 RowKey 和 ColumnFamily 查看具体写入到哪个 MemStory,并且在 MemStory 中排序;
- 向客户端发送 ack;
- 等达到 MemStore 的刷写时机后,将数据刷写到对应的 story 中 。
- 当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore 都会刷写 。当 memstore 的大小达到了hbase.hregion.memstore.flush.size(默认值 128M)* hbase.hregion.memstore.block.multiplier(默认值 4)时,会刷写同时阻止继续往该 memstore 写数据(由于线程监控是周期性的,所有有可能面对数据洪峰,尽管可能性比较小)
- 由 HRegionServer 中的属性 MemStoreFlusher 内部线程 FlushHandler 控制 。标准为LOWER_MARK(低水位线)和 HIGH_MARK(高水位线),意义在于避免写缓存使用过多的内存造成 OOM 。当 region server 中 memstore 的总大小达到低水位线java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4) * hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写 。直到 region server 中所有 memstore 的总大小减小到上述值以下 。当 region server 中 memstore 的总大小达到高水位线java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4)时,会同时阻止继续往所有的 memstore 写数据 。
- 为了避免数据过长时间处于内存之中,到达自动刷写的时间,也会触发 memstore flush 。由 HRegionServer 的属性 PeriodicMemStoreFlusher 控制进行,由于重要性比较低,5min才会执行一次 。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认1 小时) 。
- 当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,现无需手动设置,最大值为 32) 。
经验总结扩展阅读
- 电子信息工程专业和电子信息科学与技术专业有什么区别 哪个更好就业
- 生物技术专业和生物科学专业有什么区别 哪个更好就业
- 2023年10月17日适合大扫除吗 2023年10月17日大扫除好不好
- 五加三隔离政策是什么意思
- 2022大雪节气能回娘家吗
- 2023年12月7日大雪嫁娶好不好 适不适合操办婚嫁之事
- 大雪节气的诗句有哪些
- 大雪节气艾灸的好处是什么
- 2022大雪节气可以同房吗
- 属猴的2023年9月哪天结婚大吉大利








