ioremap (在用户态使用 mmap)将一段物理地址映射到内核态(或用户态)的虚拟地址空间,再对映射后的地址进行读写 。
来看一下实际读写寄存器的这两个接口,很简单就是直接读写某个地址处的数据(前提是这个地址必须经过映射) 。
#definessp_readw(addr,ret)(ret =(*(volatile unsigned int *)(addr)))#definessp_writew(addr,value)((*(volatile unsigned int *)(addr)) = (value))首先可以明确一点,读写寄存器的操作必然会经过MMU 。对于写寄存器来说,不需要考虑同步、脏数据等问题,MMU 应该是直接将这个数据写到物理地址了 。对于读寄存器来说,有 volatile 关键字的存在,这里的代码不会去优化,每次读取必须从物理地址进行读取,这里可能需要 cache 回写等操作导致导致读取的速度非常慢 。
在 u-boot 下可以直接读写物理寄存器,应该不需要这么久,几个CLK就可以完成吧?这一点我没有验证过,有测试过的朋友欢迎分享 。
总之,耗时的地方找到了,想办法优化吧 。我这里有两种优化思路:
- 查阅手册可知,SPI的内部收发部分各有一个宽度 16bit、深度为 256 的 FIFO 。我可以一次性写入不超过256字节的数据,然后使用 ssp_readw 不停地读取寄存器,直到发送 FIFO 为空 。在50MHz时钟的条件下情况下 ssp_readw 的 1.2us 延时相当于发送了8字节左右,理论上来说如果发送的数据量大于8字节,这个 1.2us 延时等于没有 。
- 每次发送1字节,加适当延时,保证发送相邻两字节之间的间隔尽量短 。
void hi_spi_delay(void){volatile unsigned int tmp = 0;while (tmp++ < 30);}void spi_write_byte(unsigned char dat){unsigned short spi_data = https://www.huyubaike.com/biancheng/0;spi_data = dat;ssp_writew(SSP_DR, spi_data);hi_spi_delay();}这个延迟函数一定要根据编译器、CPU主频、SPI时钟频率等实际测量后进行调整 。经过我的反复调整和测量,最终把循环计数设置为了30,来看一下示波器抓到的波形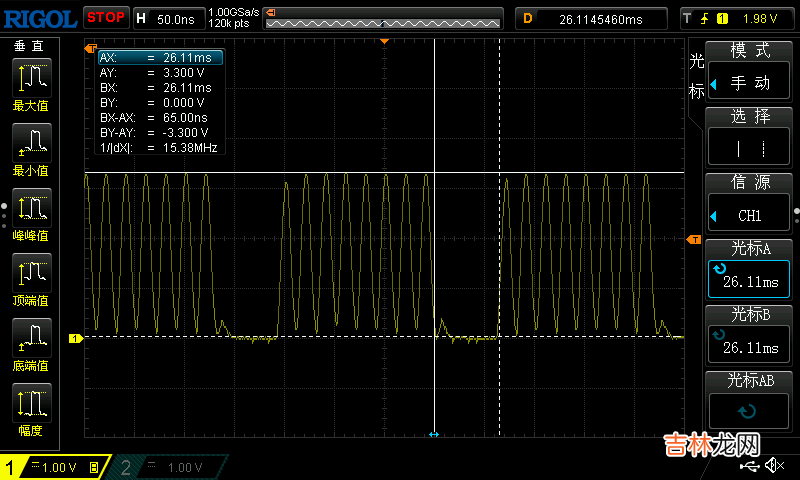
文章插图
间隔 65ns,也就是每字节耗时 225us,大约相当于 36MHz 的SPI时钟频率 。
改成其他值行不行呢?这是我的测量结果
- 30 可以保证在50MHz时钟下,每两字节之间间隔 65ns,
- 32 可以保证在50MHz时钟下,每两字节之间间隔 80ns,
- 35 可以保证在50MHz时钟下,每两字节之间间隔 100ns,但是,重点来了!循环计数小于29或不加延时的间隔是 60ns,似乎达到了某种限制,具体原因没找到,我担心有丢数据的风险,所以将循环计数设置为了30,这个值也正好是可以明显观察到延时函数有效的最小值,SPI 速率虽然没有真正达到理论值,但是对于目前的使用场景来说已经足够了 。
首先是
volatile 关键字,开发调试期间为了方便分析问题,编译优化选项往往设置为 -O0,不论加不加这个关键字都没问题,但正式程序的编译优化选项一般都会设置为
经验总结扩展阅读











- 基于vite3+tauri模拟QQ登录切换窗体|Tauri自定义拖拽|最小/大/关闭
- 痞子衡嵌入式:i.MXRT中FlexSPI外设不常用的读选通采样时钟源 - loopbackFromSckPad
- 基于tauri+vue3.x多开窗口|Tauri创建多窗体实践
- 提高工作效率的神器:基于前端表格实现Chrome Excel扩展插件
- 基于雪花算法的增强版ID生成器
- 基于QT和C++实现的翻金币游戏
- Mysql单表访问方法,索引合并,多表连接原理,基于规则的优化,子查询优化
- 基于tauri打造的HTTP API客户端工具-CyberAPI
- 基于纯前端类Excel表格控件实现在线损益表应用
- 知识图谱实体对齐2:基于GNN嵌入的方法