云时代已经来临,云上很多场景下都需要数据的迁移、备份和流转,各大云厂商也大都提供了自己的迁移工具 。本文主要介绍京东云数据库为解决用户数据迁移的常见场景所提供的解决方案 。
场景一:数据迁移上云数据迁移上云是最常见的一类场景,目前京东云提供了两个DTS(Data Transformation Service)迁移工具供选择,一个是数据迁移,一个是数据同步:
二者的主要区别如下:
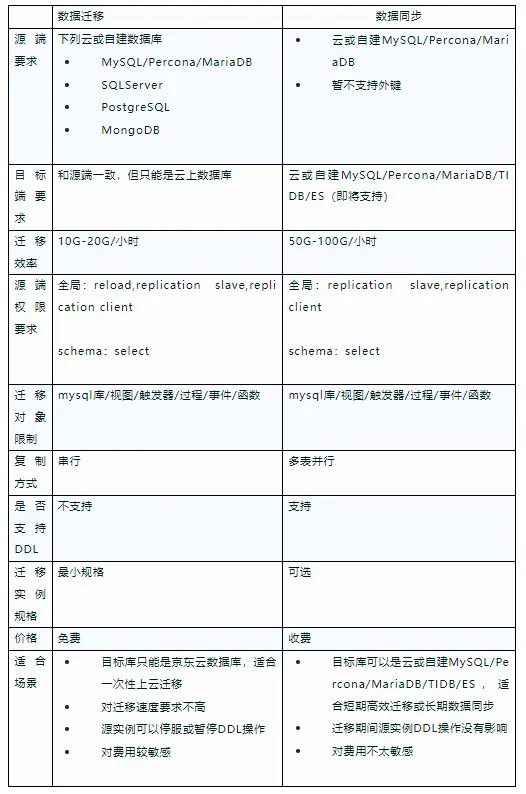
文章插图
下面是这两个工具使用中的一些常见问题:
01 两个迁移工具的原理是什么?
以MySQL为例,两个工具都有全量迁移/增量迁移/数据校验三个阶段,这三个阶段的主要原理如下:
全量阶段:
数据迁移使用mysqldump --single-transaction来取得一致性快照,但无法保证非事务引擎表的数据一致性,加上增量才可以保证数据的最终一致性,这个过程是串行操作;
数据同步使用多表并行的select方式,根据主键顺序分批获取记录,循环执行,如果没有主键,则进行全表查询 。为了最大限度减少对源实例的影响,这个过程不加锁,也不用开启事务获得一致读,因此全量期间迁移的数据是不一致的,通过增量阶段可以达到最终一致性 。所以数据同步只提供了‘全量+增量’和‘增量’两种选项,不提供单独的‘全量’选项 。
增量阶段:
数据迁移和数据同步一样,都是通过迁移启动前记录的gtid点位,抓取对应binlog同步apply到目标端,二者区别在于迁移是串行的,同步会将同一个表的事务合并后一次提交,效率更高 。
数据校验:
将源库的数据分块计算crc,每个块的元数据和校验信息记录到目标实例_jdts_check为前缀的库下checksum表中 。目标库同步完成后根据同样算法进行计算,比较对应块号的crc值是否一致来判断校验是否成功 。
02 迁移速度可以调整吗?
数据迁移不可以,数据同步可以选择更大的迁移实例和增加更多的并发来调整,但由于并发机制是基于表粒度的,对于少量大表的情况,增加并发并不会有明显作用 。
03 迁移进度为什么显示超过100%?
为了效率更高,迁移显示的进度是根据已经迁移的记录数除以数据字典记录的记录数显示,数据字典的值并不完全准确,因此理论上会出现进度超过100%的现象 。
04 迁移延时为什么很长?
大多情况是源库写操作压力大导致目标库binlog apply进度赶不上源库的写入速度,也有可能是目标库读写压力大或者迁移实例压力大,具体需要联系京东云技术服务及时介入 。
05 迁移期间目标库是否可以读写数据?
理论上可以读写,但不建议在迁移期间操作,主要有两个弊端:
- 写入脏数据会导致校验不一致 。
- 读写数据会导致目标库压力增大,减缓数据同步速度 。
不会的,如果目标库库表有数据,预检的时候会报错不通过;如果是空的库表,则可以直接写入 。
07 自检提示源或目标库网络不通怎么办?
检查源库和目标库的白名单限制,需要加上dts迁移实例的ip,在迁移任务配置的时候会在页面提示 。
08 目标库中的_jdts为前缀的库可以删除吗?
迁移完成可以删除 。
09 可以从只读实例同步吗?
只要源实例是gtid方式复制的,都可以通过主实例或只读实例同步 。
10 数据迁移选择内网时,为啥只能用json格式,不能图形化选择库表?
因为数据迁移创建任务的时候,迁移实例还未创建,无法判断内网连通性;数据同步已经做了改进,内外网均可以通过图形化方式选择库表 。
经验总结扩展阅读














- 阿莫和赤云是什么电视剧中的人物?
- 云南人参果怎么吃
- 华为云相册登陆 华为云相册登陆
- 茶膏是什么
- SpringCloud怎么迈向云原生?
- 冰岛茶产地在哪里
- 云南四大名鱼
- 少前:云图计划武装印记的开启方法是什么
- 纳西族在云南哪个地方
- 多可用区 亚马逊云 RDB数据故障转移