AnalysisCoreset 是带有权重的数据子集,目的是在某个方面模拟完整数据的表现(例如损失函数的梯度,既可以是在训练数据上的损失,也可以是在验证数据上的损失);
给出优化目标的定义:
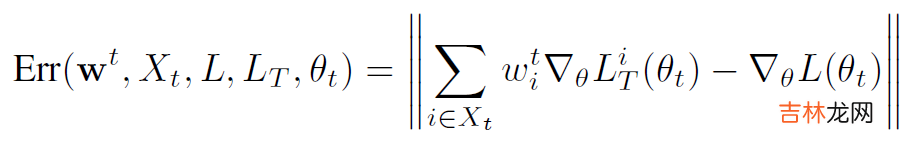
文章插图
$w^t$ 是 t 轮得到的 coreset 权重,$X_t$ 是 t 轮得到的 coreset,$L$ 既可以是在训练数据上的损失,也可以是在验证数据上的损失,$L_T$ 是在 coreset 上的损失函数,$\theta_t$ 是 t 轮得到模型参数;
【论文笔记 - GRAD-MATCH: A Gradient Matching Based Data Subset Selection For Efficient Learning】最小化 ERR 来使 Coreset 最好地模拟损失函数(训练集或验证集)的梯度 。
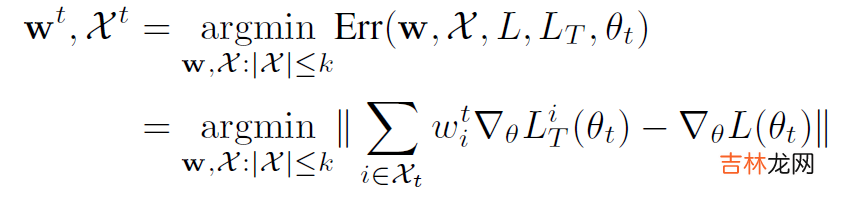
文章插图
如何优化这个问题
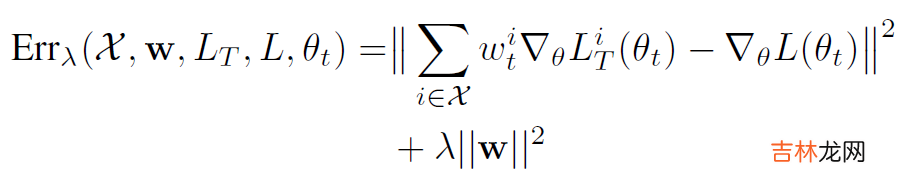
文章插图
将其转化为次模函数:
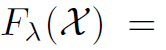
文章插图
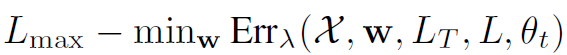
文章插图
之后可以用贪心算法快速解决 。
Tricks
- 只计算最后一层的梯度;
- 现在完整的数据集上跑几个 epoch,获得一个较为靠近的模型权重(类似于 warm-up 和 pre-training);
- 每过 R 个 epoch 再更新 coreset 。
经验总结扩展阅读











- MFC 学习笔记
- 论文笔记 - SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
- JVM学习笔记——类加载和字节码技术篇
- Agda学习笔记1
- 萌新版 xss学习笔记
- MyBatis笔记03------XXXMapper.xml文件解析
- 我的Spark学习笔记
- 7000-8000高性价比笔记本排行榜2022-7000-8000值得买的笔记本排行榜
- JVM学习笔记——垃圾回收篇
- 黑莓q5用安装微信的方法a 用黑莓自带的印象笔记手敲的 看不懂的宝宝们在私聊我吧