文章插图
公式如下:

文章插图
分析一下 , 会发现 , SAGA模式中ApplyEdge和ApplyVertex是传统deep learning中的NN(Neural Network)操作 , 我们可以复用;而Scatter和Gather是GNN新引入的操作 。即 , Graph Computing = Graph Ops + NN Ops 。
【GNN 101】
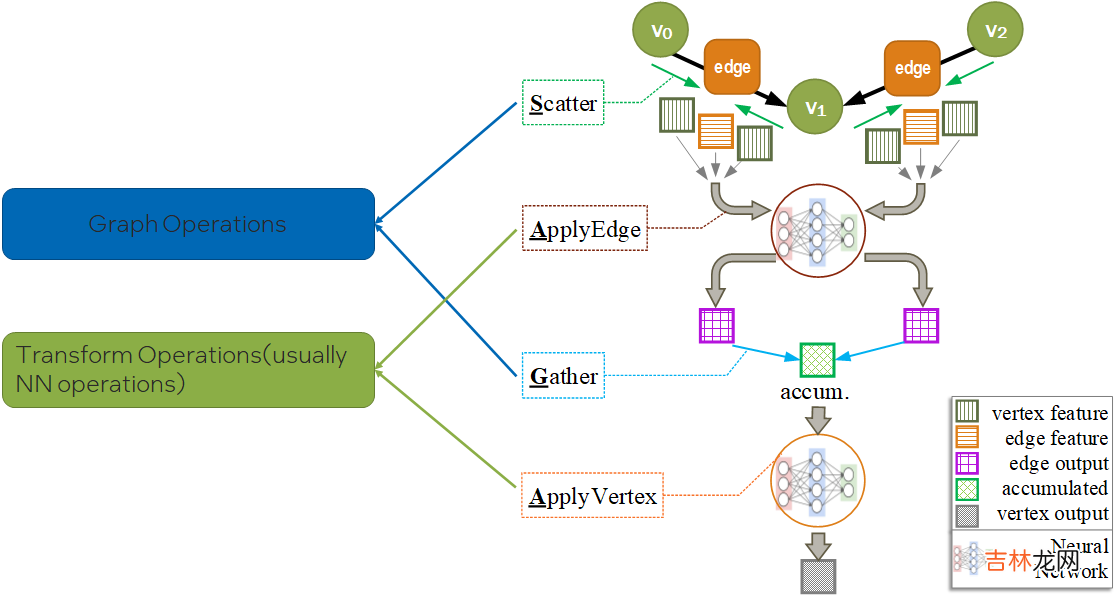
文章插图
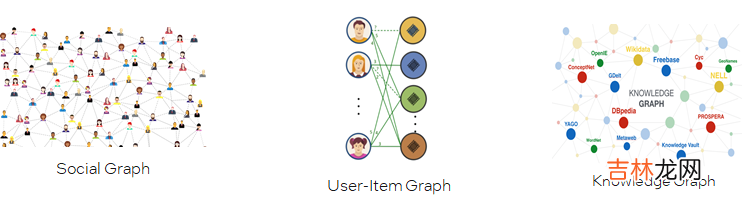
不同的图数据集规模
- One big graph 可能高达数十亿的结点 , 数百亿的边 。
文章插图
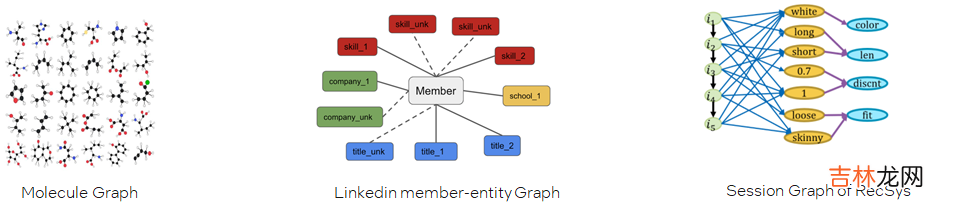
- Many small graphs
文章插图
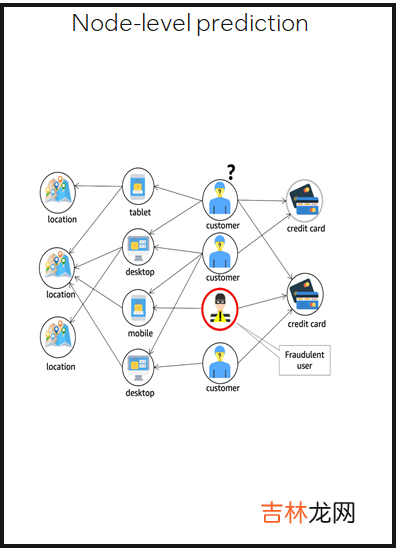
不同的图任务
- Node-level prediction 预测图中结点的类别或性质
文章插图
- Edge-level prediction 预测图中两个结点是否存在边 , 以及边的类别或性质
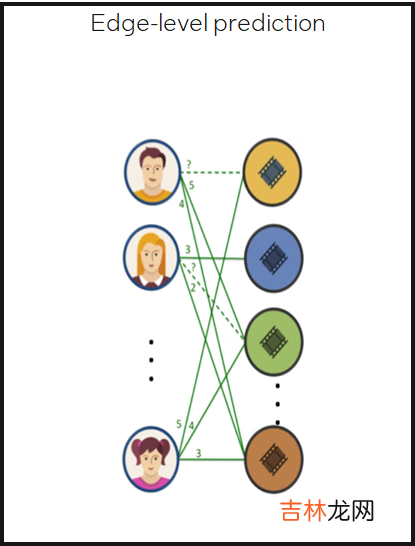
文章插图
- Graph-level prediction 预测整图或子图的类别或性质
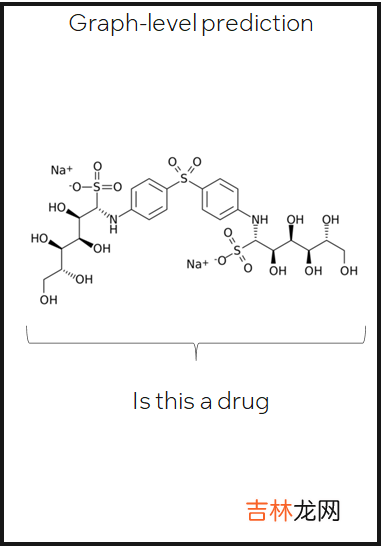
文章插图
HowWorkflow
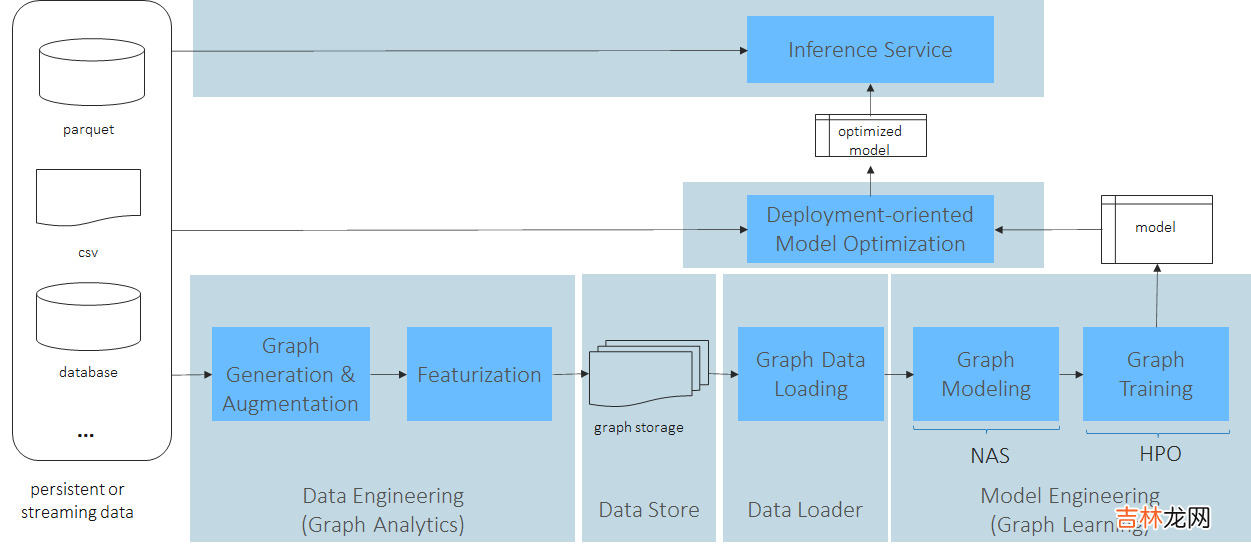
文章插图
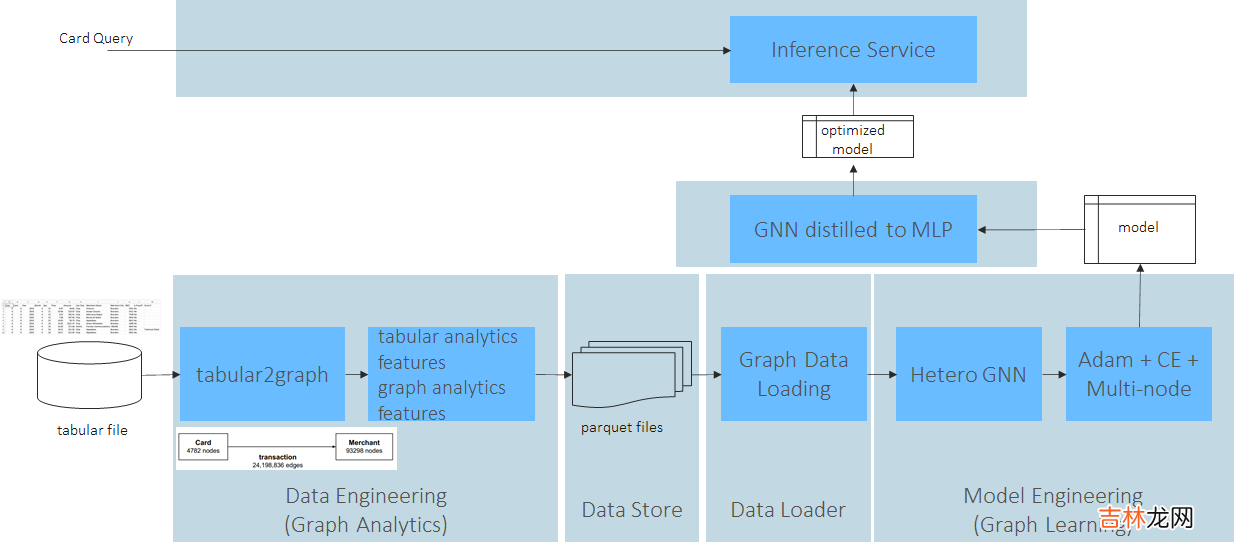
以fraud detection为例:软件栈
- Tabformer数据集
文章插图
- workflow
文章插图
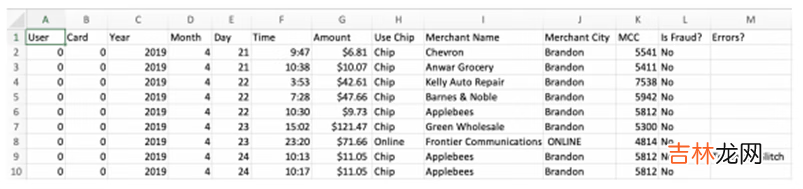
文章插图
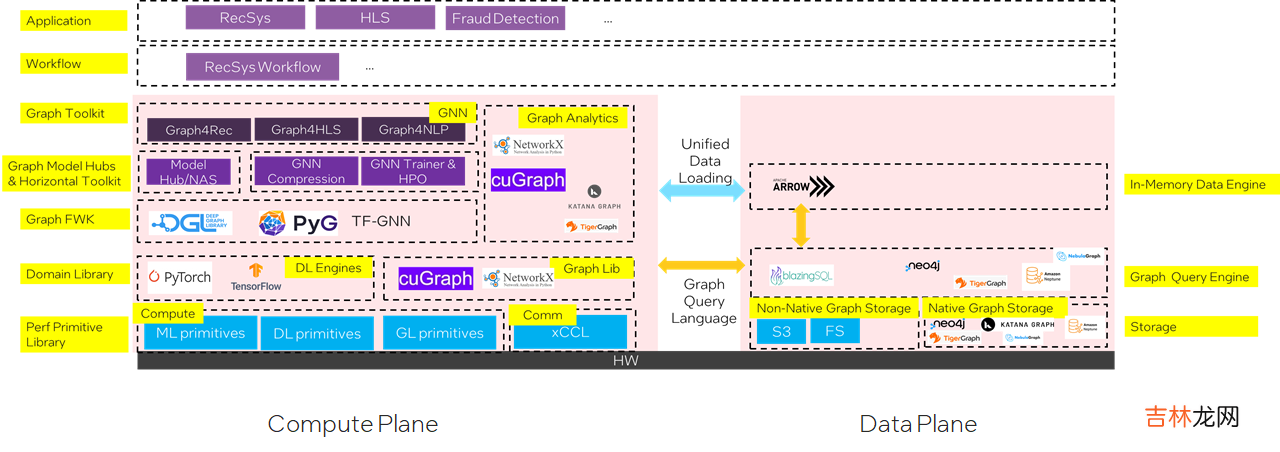
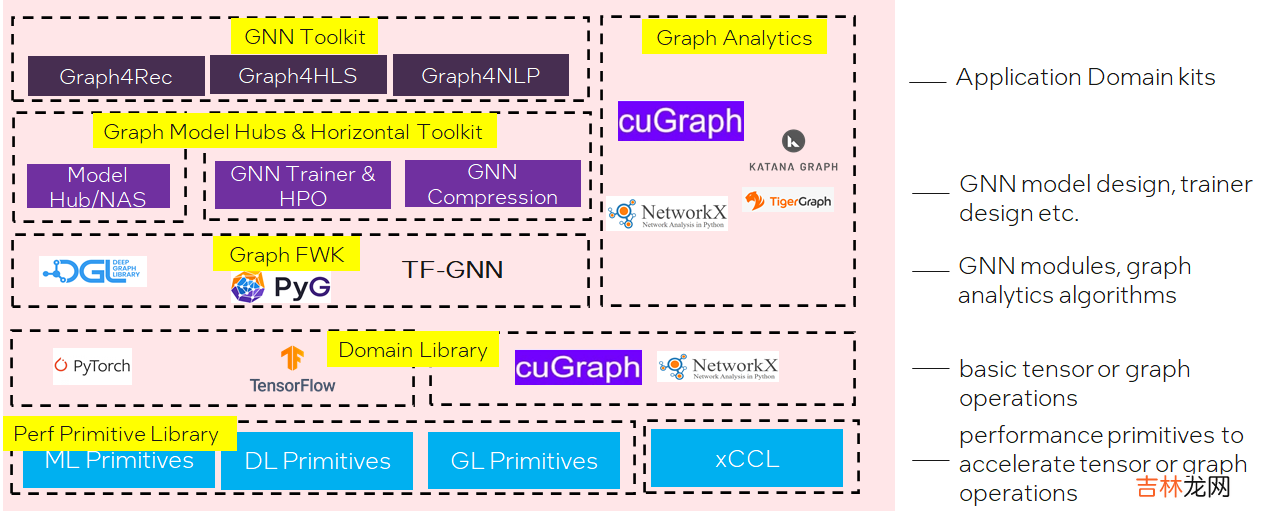
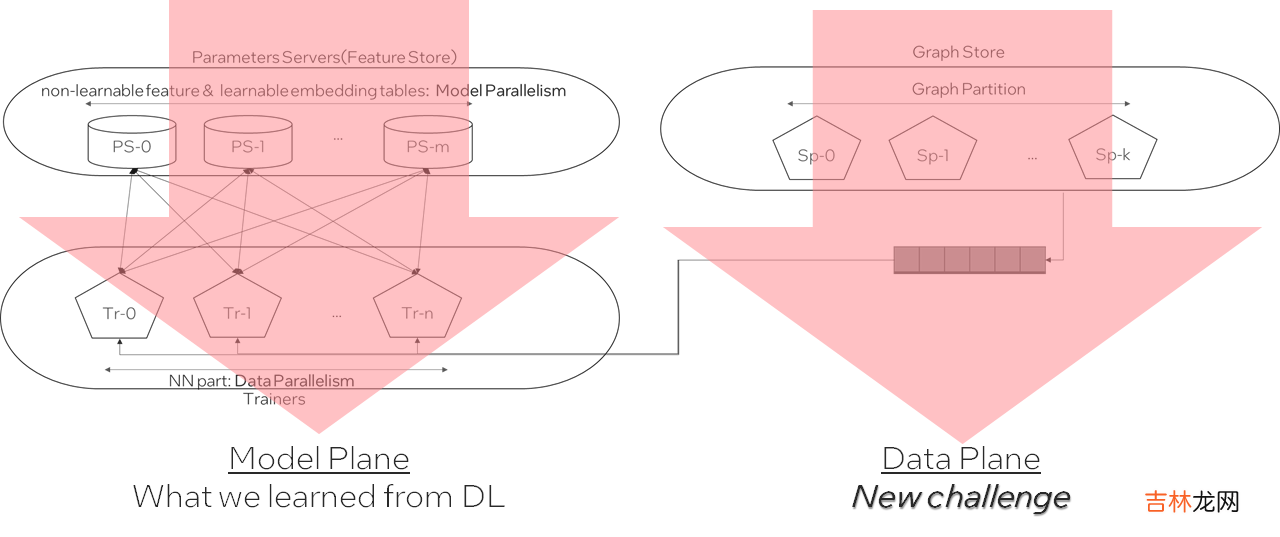
- 计算平面
文章插图
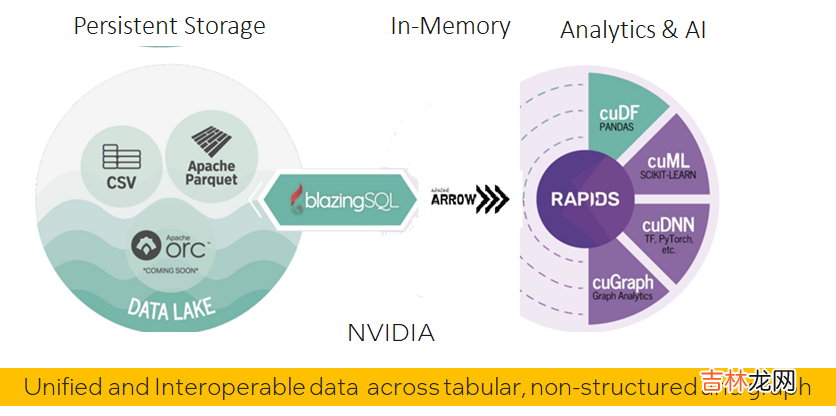
- 数据平面
文章插图
SW ChallengesGraph SamplerFor
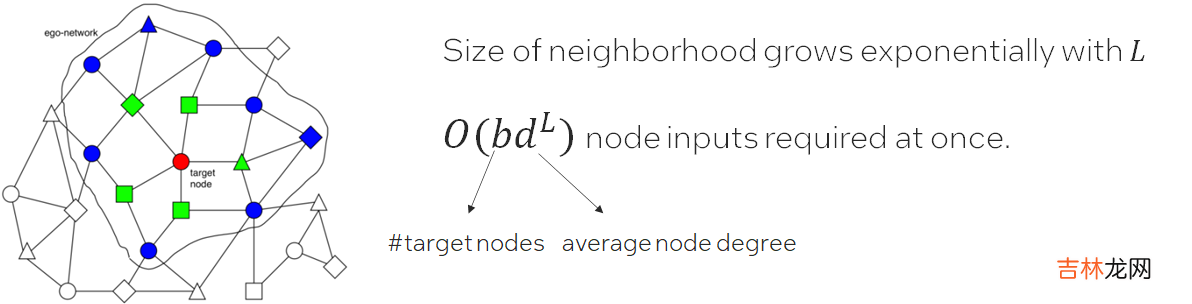
many small graphs datasets, full batch training works most time. Full batch training means we can do training on whole graph; When it comes to one large graph datasets, in many real scenarios, we meet Neighbor Explosion problem;Neighbor Explosion:Graph sampler comes to rescue. Only sample a fraction of target nodes, and furthermore, for each target node, we sample a sub-graph of its ego-network for training.This is called mini-batch training. Graph sampling is triggered for each data loading.And the hops of the sampled graph equals the GNN layer number . Which means graph sampler in data loader is important in GNN training.
文章插图

文章插图
Challenge: How to optimize sampler both as standalone and in training pipe?
When graph comes to huge(billions of nodes, tens of billions of edges), we meet new at-scale challenges:
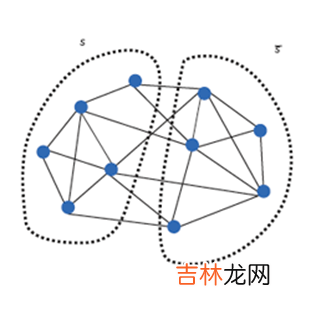
- How to store the huge graph across node? -> graph partition
- How to build a training system w/ not only distributed model computing but also distributed graph store and sampling?
- How to cut the graph while minimize cross partition connections?
- How to cut the graph while minimize cross partition connections?
文章插图
A possible GNN distributed training architecture:
文章插图
经验总结扩展阅读












- 创造101王一博跳主题曲是哪一期?
- 上海迪士尼身高102cm要买票吗 上海迪士尼身高101会查吗
- 知识图谱实体对齐2:基于GNN嵌入的方法
- 110104属于北京哪个区
- 肖战上101是哪一期?
- 恋爱101度王俊相亲第几集?
- 101孟美岐撑腰是哪一期?
- 如何评价西决G7火箭92101输给勇士
- 如何评价因创造101而爆火的麦锐电影获数千万元A轮融资
- 101胶水怎么去除