其他答主并没有正面解答你的问题 。
线性回归是对已有数据进行学习,学习到一种模式,这样就可以对其他数据做预测了 。
y = β1 x + β0
使用上式对数据建模时,线性是指,y和x之间是线性的关系,即y和x组成了一条直线,用这个直线来描述数据集中的数据 。在线性回归建模的过程,其实是寻找一个最优的直线,来拟合所有数据 。
【线性回归中的线性指的是什么,线性回归中的小r表示什么】
在对收入数据集进行建模时 , 我们可以对参数β0和β1取不同值来构建不同的直线,这样就形成了一个参数家族 。参数家族中有一个最佳组合,可以在统计上以最优的方式描述数据集 。那么监督学习的过程就可以被定义为:给定N个数据对,寻找最佳参数β0和β1,使模型可以更好地拟合这些数据 。
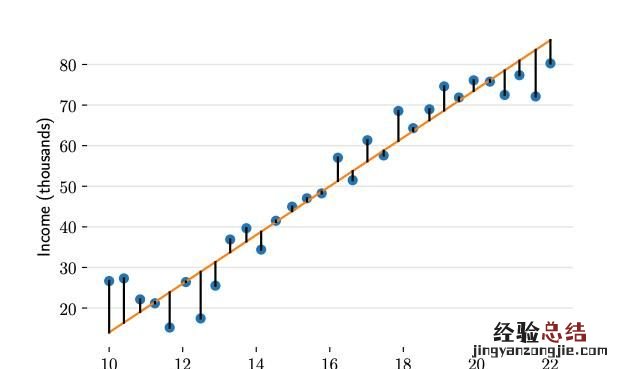
上图以及你问题中的图 , 出现了不同的直线,到底哪条直线是最佳的呢?如何衡量模型是否以最优的方式拟合数据呢?机器学习用损失函数(loss function)的来衡量 。损失函数又称成为代价函数(cost function),它计算了模型预测值y和真实值y之间的差异程度 。从名字也可以看出,这个函数计算的是模型犯错的损失或代价,损失函数越大,模型越差,越不能拟合数据 。统计学家通常使用”L”来表示损失函数 。
线性回归的损失函数是误差平方的求和 。
对于给定数据集,x和y的值是已知的,参数β0和β1是需要求解的 。线性回归其实就是要求解使损失函数最小的β0和β1 。
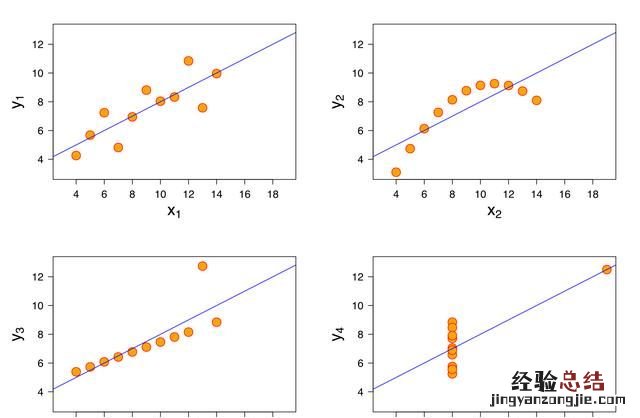
那到底什么时候可以使用线性回归呢?统计学家安斯库姆给出了四个数据集,被称为安斯库姆四重奏,从这四个数据集的分布可以看出 , 并不是所有的数据集都可以用一元线性回归来建模 。现实世界中的问题往往更复杂,变量几乎不可能非常理想化地符合线性模型的要求 。因此使用线性回归,需要遵守下面几个假设:
- 线性回归是一个回归问题(regression) 。
- 要预测的变量与自变量的关系是线性的 。
- 各项误差服从正太分布,均值为0,与同方差 。
- 变量 的分布要有变异性 。
- 多元线性回归中不同特征之间应该相互独立,避免线性相关 。
与回归相对的是分类问题(classification),分类问题要预测的变量输出集合是有限的,预测值只能是有限集合内的一个 。当要预测的变量y输出集合是无限且连续,我们称之为回归 。比如 , 天气预报预测明天是否下雨,是一个二分类问题;预测明天的降雨量多少,就是一个回归问题 。
变量之间是线性关系
线性通常是指变量之间保持等比例的关系,从图形上来看,变量之间的形状为直线,斜率是常数 。这是一个非常强的假设,数据点的分布呈现复杂的曲线 , 则不能使用线性回归来建模 。可以看出 , 四重奏右上角的数据就不太适合用线性回归的方式进行建模 。
误差服从均值为零的正太分布
前面最小二乘法求解过程已经提到了误差的概念,误差可以表示为“实际值-真实值” 。
可以这样理解这个假设:线性回归允许预测值与真实值之间存在误差 , 随着数据量的增多,这些数据的误差平均值为0;从图形上来看,各个真实值可能在直线上方,也可能在直线下方,当数据足够多时,各个数据上上下下相互抵消 。如果误差不服从均值为零的正太分布 , 那么很有可能是出现了一些异常值 , 数据的分布很可能是安斯库姆四重奏右下角的情况 。
这也是一个非常强的假设,如果要使用线性回归模型,那么必须假设数据的误差均值为零的正太分布 。
变量x的分布要有变异性
线性回归对变量x也有要求,要有一定变化,不能像安斯库姆四重奏右下角的数据那样,绝大多数数据都分布在一条竖线上 。
多元线性回归不同特征之间相互独立
如果不同特征不是相互独立 , 那么可能导致特征间产生共线性,进而导致模型不准确 。举一个比较极端的例子,预测房价时使用多个特征:房间数量 , 房间数量 * 2,房间数量* 0.5等,特征之间是线性相关的,如果模型只有这些特征,缺少其他有效特征 , 虽然可以训练出一个模型,但是模型不准确,预测性差 。