你好 , 想要识别图片中的文字 , 现在有很多软件都支持 , 这里推荐您使用闪电OCR图片文字识别软件,下面是详细视频教学,希望能帮到你哦!
工具地址:
***/ocr
视频教学:
ABBYY FineReader PDF 的特色是采用了 ABBYY 新推出的基于 AI的OCR 技术,可以更轻松地在同一工作流程中对各种文档进行数字化、检索、编辑、加密、共享和协作 。
现在 , 信息工作者能将更多时间和精力投入到他们的专业领域而花费较少的时间处理行政工作 。
识别提取图片中的文字的具体操作步骤如下:
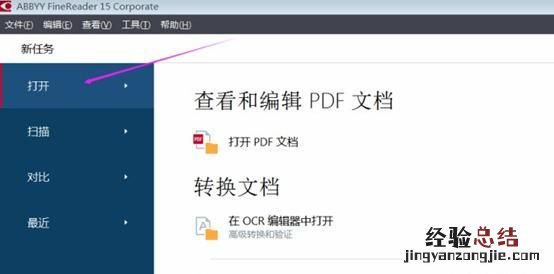
图1:启动软件
1.提取文字第一步
启动ABBYY FineReader 15 , 弹出如图2所示画面,这是软件运行后的初始画面 。这里需要打开图1的图片,所以点击打开标签 。
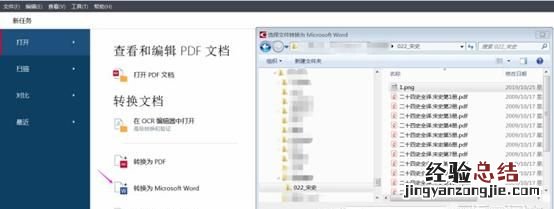
图2:打开文件
2.提取文字第二步
在“打开”标签下,选择一种转换类型,因为要转换的是图片上的一段文字,所以这里使用Word文档格式 。单击“转换为Microsoft Word”,会弹出图3所示对话框,找到图1截图所在文件,点击打开 。
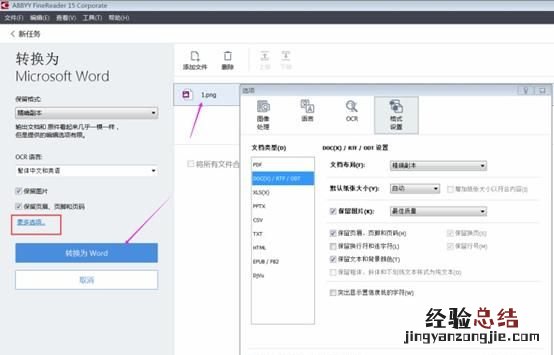
图3:设置转换选项
3.提取文字第三步
打开图片后,便可以设置转换文件的选项了 。由于这个文档为繁体中文,因此首先要把OCR语言设置成繁体 。点开“更多选项”,如图4所示,在弹出的窗口内设置选项及格式等 。

图4:转换文件
4.提取文字第四步
设置好选项后 , 点击“转换为Word”按钮(如图5中箭头位置),弹出如图5所示的保存对话框 , 选着文件的保存路径,输入名称,选择保存类型,点击保存 。之后系统会需要一点时间来处理转换过程 。
图5:转换文件读条
图6是转换文件的读条,图1的截图文字较少,这个读条的时间也很短 。值得注意的是,如果需要转换长篇的文章,则建议事先关闭电脑中的其他应用程序,并且需要等待一定的时间 。
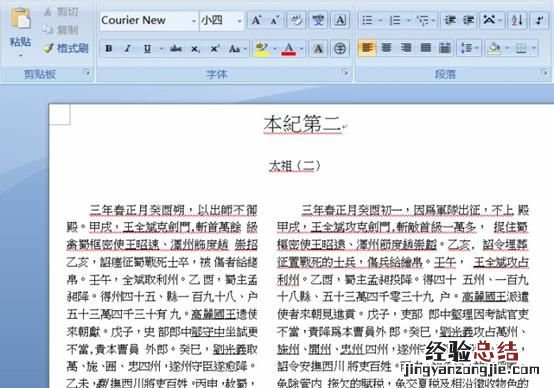
图6:转换后的文件
5.提取文字第五步
【什么软件可以识别图片中的文字并读出来】
最后是对生成的文本进行校验 。图7是生成的文本经过校验前后的对比 。显而易见的,ABBYY FineReader的文字识别功能相当强大 。通过对图7文件的校验没有发现错误,准确率达到了100% 。