PSIN 谣言检测——《Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media》( 二 )
News event 定义:$T_{i}=\left\{p_{1}^{i}, p_{2}^{i}, \ldots p_{M_{i}}^{i}, G_{i}^{P}, u_{1}^{i}, u_{2}^{i}, \ldots u_{N_{i}}^{i}, G_{i}^{U}, G_{i}^{U P}\right\}$
News event can be considered as a heterogeneous graph two types of nodes: post and user, and three types of edges: post-post, user-user and user-post.as shown in Figure 2:
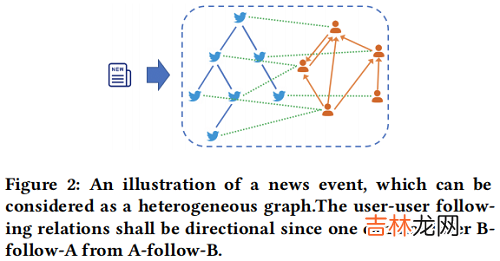
文章插图
在本文的数据集中,每一个 $T_i$ 均有一个主题标签 $y_{i}^{C} \in\{ Politics, Entertainment, Health, Covid-19, Sryia War\}$ 和 groundtruth veracity label $y_{i}^{V} \in\{F, R\}$ (i.e. Fake, news or Real news) 。
问题目标:ProbleM 1. Given the training set $\mathcal{T}_{\text {train }}=\left\{\mathrm{T}_{\text {train }}, Y_{\text {train }}^{V}, Y_{\text {train }}^{C}\right\}$ , and the testing set $\mathcal{T}_{\text {test }}=\left\{\mathrm{T}_{\text {test }}\right\}$ , how to learn a classifier $f: T_{i} \rightarrow y_{i}^{v} from \mathcal{T}_{\text {train }}$ and then predict the veracity label $Y_{\text {test }}$ for $\mathcal{T}_{\text {test }} $.4 Methodlogy谣言检测是个异质图分类问题,由于谣言检测数据集的特殊性:post-post 之间的子图结构和 user-user 之间的子图结构有显著差别,所以本文采取分治的策略 。图结构被划分为三部分:post propagation tree、user social graph、post-user interaction graph总体框架如下:
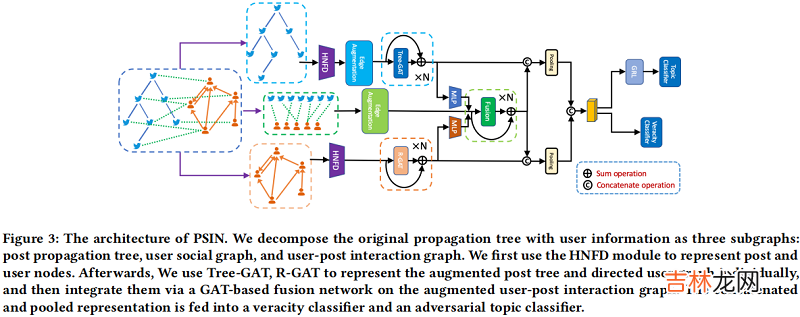
文章插图
4.1 Hybrid Node Feature Encoder对于 event $i$ $T_{i}$,节点集合 $\left\{p_{1}^{i}, p_{2}^{i}, \ldots p_{M_{i}}^{i}, u_{1}^{i}, u_{2}^{i}, \ldots u_{N_{i}}^{i}\right\}$,每个节点拥有 textual features 和 meta features 。Post 和 user 的 meta feature 如下:
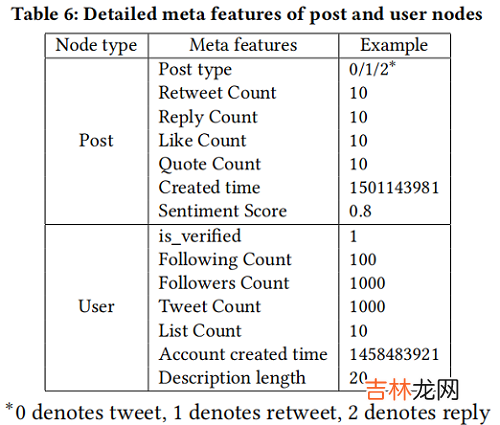
文章插图
4.1.1 Text Content Encoding常用的文本编码方式:TF-IDF、CNN、LSTM、Transformer、BERT 。
本文的文本词向量通过 CNN 获得,设 $c_j$ 为第 $j$ 个节点提取的文本嵌入 。
4.1.2 Meta feature based Gate Mechanism文本嵌入压缩了重要的语义信息,然而,每个节点的重要性是不同的 。直观地说,转发数或关注者数等元特征(meta feature)意味着受欢迎程度和社会关注,这可用来推断给定节点的重要性 。因此,设计了一个基于元特征的门机制来过滤文本特征,如 Figure 4 所示 。
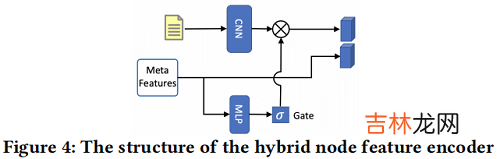
文章插图
具体来说,给定第 $j$ 个节点的元特征 $m_j$,我们计算其贡献分数,以衡量第 $j$ 个节点的文本特征的重要性:
$g_{j}=\sigma\left(\mathbf{W}^{m} \mathbf{m}_{j}+\mathbf{b}^{m}\right)$
其中 $\sigma$ 是一个激活函数,它将输入映射到 $[0,1]$ 中,$\mathbf{W}^{m}$ 和 $\mathbf{b}^{m}$ 都是可训练的参数 。最后,第 $j$ 个节点的表示如下:
$\mathbf{n}_{j}=g_{j} \mathbf{c}_{j} \oplus \mathbf{m}_{j}$
其中,$\oplus$ 是连接操作符 。因此,给定输入序列 $\left\{p_{1}, p_{2}, \ldots p_{M}, u_{1}, u_{2}, \ldots u_{N}\right\}$ 对于第 $i$ 个新闻事件,我们得到帖子特征矩阵 $\mathbf{P}=\left\{\mathbf{h}_{1}^{P}, \mathbf{h}_{2}^{P}, \ldots, \mathbf{h}_{M}^{P}\right\}$ 和用户特征矩阵 $\mathbf{U}=\left\{\mathbf{h}_{1}^{U}, \mathbf{h}_{2}^{U}, \ldots \mathbf{h}_{N}^{U}\right\}$ 。
4.2 Post Tree Modeling
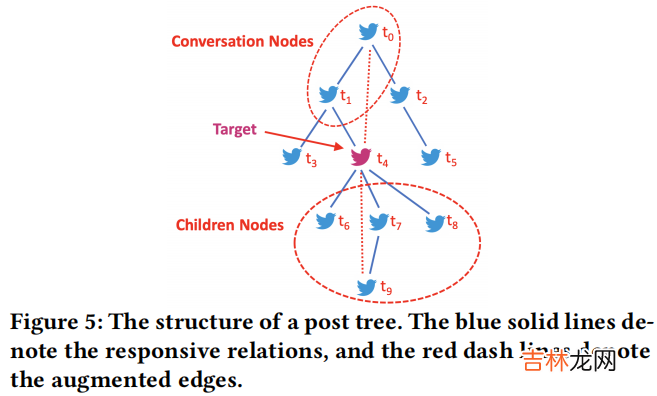
文章插图
采用图结构建模的原因:
1:帖子深层之后任然存在联系,尤其是对于源推文极具争议性的时候;
2:回复贴对于源帖的密切回复;
本文提出的图结构信息建模的方法是:Tree-GAT,包括两个模块:
经验总结扩展阅读













- PLAN 谣言检测——《Interpretable Rumor Detection in Microblogs by Attending to User Interactions》
- 谣言检测——《Debunking Rumors on Twitter with Tree Transformer》
- 如何检测手机
- 水质检测笔多少为正常
- 翅尖有毒是谣言吗
- 核酸检测阳性怎么办
- 自身 如何在linux下检测IP冲突
- 华为watch3pro支持血糖检测吗_华为watch3pro有测血糖功能吗
- 东莞机动车检测站周末上班吗
- Notebook交互式完成目标检测任务