xxl-job
是一款国产开发的轻量级分布式调度工具,但功能比海豚调度少 。
其不依赖于大数据组件,而是依赖于MySQL,和海豚调度的依赖项是一样的 。
Elastic-Job
是基于Quartz 二次开发的弹性分布式任务调度系统,初衷是面向高并发且复杂的任务 。
设计理念是无中心化的,通过ZooKeeper的选举机制选举出主服务器,如果主服务器挂了,会重新选举新的主服务器 。
因此elasticjob具有良好的扩展性和可用性,但是使用和运维有一定的复杂度 。
Azkaban
Azkaban也是一个轻量级的任务调度框架,但其缺点是可视化支持不好,任务必须通过打一个zip包来进行实现,不是很方便 。
AirFlow
AirFlow是用Python写的一款任务调度系统,界面很高大上,但不符合中国人的使用习惯 。
需要使用Python进行DAG图的绘制,无法做到低代码任务调度 。
Oozie
是集成在Hadoop中的大数据任务调度框架,其对任务的编写是需要通过xml语言进行的 。
04 选择DolphinScheduler的理由1、部署简单,Master、Worker各司其职,可线性扩展,不依赖于大数据集群
2、对任务及节点有直观的监控,失败还是成功能够一目了然
3、任务类型支持多,DAG图决定了可视化配置及可视化任务血缘
4、甘特图和版本控制,对于大量任务来说,非常好用
5、能够很好满足工作需求
大数据平台架构
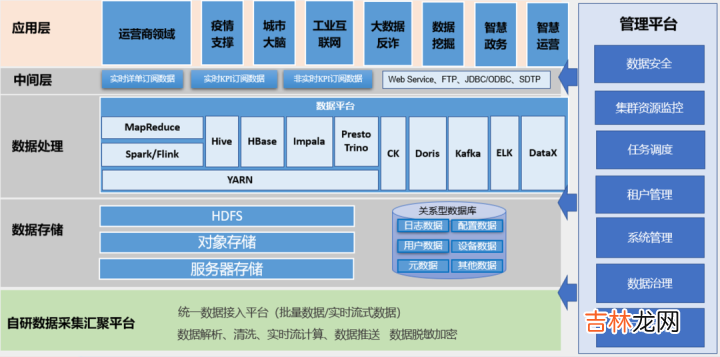
文章插图
?
数据流图

文章插图
?
海量数据处理01 数据需求数据量:每天上千亿条
字段数:上百个字段,String类型居多
数据流程:在数据仓库中进行加工,加工完成的数据放入CK,应用直接查询CK的数据
存储周期:21天~60天
查询响应:对于部分字段需要秒级响应
02 数据同步选型

文章插图
?
Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,在DolphinScheduler上也集成了Sqoop的任务调度,但是对于从Hive到ClickHouse的需求,Sqoop是无法支持的 。
Flink
通过DS调度Flink任务进行或者直接构建一套以Flink为主的实时流计算框架,对于这个需求,不仅要搭建一套计算框架,还要加上Kafka做消息队列,除此之外有增加额外的资源开销 。
其次需要编写程序,这对于后面的运维团队是不方便的 。
最后我们主要的场景是离线,单比较吞吐量的话,不如考虑使用Spark 。
Spark&SparkSQL
在不考虑环境及资源的情况下,Spark确实是最优选择,因为我们的数据加工也是用的SparkSQL,那现在的情况就是对于数据同步来说有两种方式去做 。
第一种是加工出来的数据不持久化存储,直接通过网络IO往ClickHouse里面去写,这一种方式对于服务器资源的开销是最小的,但是其风险也是最大的,因为加工出来的数据不落盘,在数据同步或者是ClickHouse存储中发现异常,就必须要进行重新加工,但是下面dws、dwd的数据是14天清理一次,所以不落盘这种方式就需要再进行考虑 。
第二种方式是加工出来的数据放到Hive中,再使用SparkSQL进行同步,只是这种的话,需要耗费更多的Yarn资源量,所以在一期工程中,因为资源量的限制,我们并没有使用SparkSQL来作为数据同步方案,但是在二期工程中,得到了扩容的集群是完全足够的,我们就将数据加工和数据同步全部更换为了SparkSQL 。
经验总结扩展阅读










- 大数据技术之HBase原理与实战归纳分享-中
- 巧用VBA实现:基于多个关键词模糊匹配Excel多行数据
- JuiceFS 元数据引擎选型指南
- 碧蓝航线核心数据怎么得
- 极限挑战岳云鹏当嘉宾哪一期
- Docker | 容器数据卷详解
- 如何优雅的备份MySQL数据?看这篇文章就够了
- 开心消消乐重新安装数据会恢复吗
- 大数据技术之HBase原理与实战归纳分享-上
- 07 ClickHouseClickHouse数据库引擎解析