执行一次checkpoint的操作可以分为两个步骤:
- 计算当前系统中可以覆盖的redo日志对应的lsn最大是多少
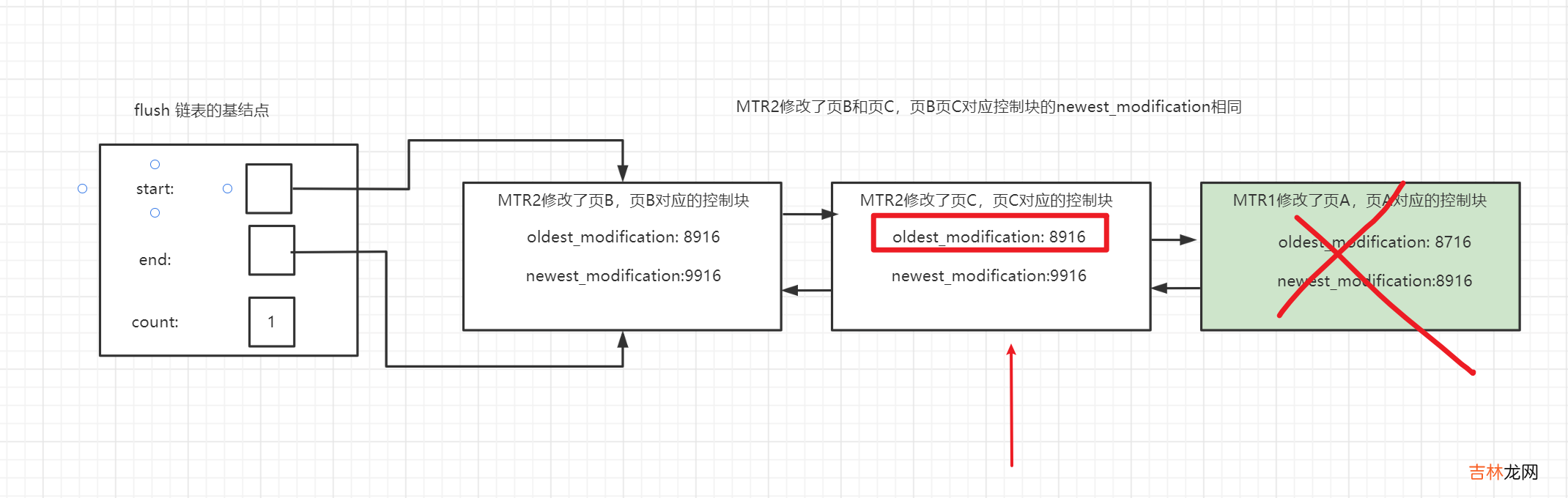
文章插图
比如页A已经被刷盘了 , 此时flush链表的尾部便是页C , 其oldest_modification=8916那么说明redo log日志对应lsn值小于8916的均可被覆盖 ,checkpoint_lsn的值会被设置为8916
- 将checkpoint_lsn和对应的日志文件组偏移量和这次checkpoint的编号写入到日志文件的管理信息中(checkpoint1 , checkpoint2)
innodb使用checkpoint_no记录当前系统执行了多少次checkpoint , 根据lsn值计算除redo log日志的偏移量(lsn初始值为8704 , redo日志文件组偏移量为2048)计算得到checkpoint_offset,将checkpoint_no,checkpoint_lsn,checkpoint_offeset写回到redo log日志文件组管理信息中 , 关于checkpoint的信息 , 当checkpoint_no为偶数的时候会写回到checkpoint1 , 反之写入到checkpoint2中 。
innodb_flush_log_at_trx_commit配置项 , 来进行控制 。其选项值的不同代表着不同的策略:- 0:表示事务提交不立即向磁盘同步redo log , 而是交由后台线程处理 。这样的好处时加快处理请求的速度 , 但是如果服务崩溃 , 后台线程也没来得及刷新redo log , 这时候会丢失事务对页面的处理
- 1:表示每次事务提交都需要将redo log同步到磁盘 , 可以保证事务的持久性 , 这也是
innodb_flush_log_at_trx_commit的默认值 - 2:表示事务提交时 , 将redo log写到操作系统的缓冲区中 , 但是并不需要真正持久化到磁盘 , 这样事务的持久性在操作系统没有崩溃的时候还是可以保证 , 但是如果操作系统也崩溃那么还是无法保证持久性
从对应lsn的值为checkpoint_lsn的redo log开始恢复redo log日志文件组有checkpoint1和checkpoint2记录checkpoint_lsn的值 , 我们需要选取最近发生的checkpoint信息 , 也就是将二者中的checkpoint_no拿出来比较比较 , 谁大说明谁存储了最近一次checkpoint信息 , 从而拿到最近发生checkpoint的checkpoint_lsn以及其对应的在redo 日志文件组中偏移量checkpoint_offset
2.确定恢复的终点

文章插图
写入redo log到redo日志文件中redo log block中时 , 是顺序写入的 , 先写满一个block再写下一个block , 每一个block的log block header部分有一个
log_block_hdr_data_len来记录当前lock block使用了多少字节(从12开始 , 因为lock block header占用了12字节) , 随着越来越多的日志写入block最后最大为512字节`,所有如果此值小于512那么说明 , 当前这个block就是崩溃恢复需要扫描的最后一个block 。
经验总结扩展阅读












- MySQL的下载、安装、配置
- 我的Vue之旅 09 数据数据库表的存储与获取实现 Mysql + Golang
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
- Mysql InnoDB Buffer Pool
- 「MySQL高级篇」MySQL锁机制 && 事务
- 【MySQL】Navicat15 安装
- 「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
- 「MySQL高级篇」MySQL索引原理,设计原则
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?