一丶什么是redoinnodb是以也为单位来管理存储空间的 , 增删改查的本质都是在访问页面 , 在innodb真正访问页面之前 , 需要将其加载到内存中的buffer pool中之后才可以访问 , 但是在聊事务的时候 , 事务具备持久性,如果只在内存中修改了页面 , 而在事务提交后发生了系统崩溃 , 导致内存数据丢失 , 就会发生提交事务所作的更改还没来得及持久化到磁盘 。
那么如何保证到提交的事务 , 所作更改一定持久化到磁盘了昵?
最简单粗暴的固然是 , 每次事务提交都将其所作更改持久化到磁盘 。这种操作又存在如下问题:
- 刷新一个完整的页面 , 十分浪费IO , 有时候事务所作的更改只是一个小小的字节 , 但由于innodb是以页为单位的对磁盘进行io操作的 , 这时候需要把一个完整的页刷新到磁盘 , 为了一个字节刷新16k的内容 , 是不划算的
- 随机io刷新缓慢 , 一个事务包含多个数据库操作 , 一个数据库操作包含对多个页面的修改 , 比如修改的数据不在相邻的页 , 存在多个不同的索引B+树需要维护 , 这时候需要刷新这些零散的页面 , 进行大量的随机IO
在事务提交的时候只记录下 , 事务做了什么变更到redolog , 中这样即使系统崩溃了 , 重启之后只需要按照redo log上的内容进行恢复 , 重新更新数据页 , 那么该事务还是具备持久性的 , 这便是重做日志——redo log 。使用redo log的好处:
- redo log占用空间小:在存储事务所作变更的时候 , 需要存储变更数据页所在的表空间 , 页号 , 偏移量以及需要更新的值时 , 需要的空间很少 。
- redo log是顺序写入磁盘的 , 在执行事务的过程中 , 在执行每一条语句的时候 , 就可能产生若干条redo log , 这些日志都是按照产生的顺序写入磁盘的 , 也就是使用顺序io
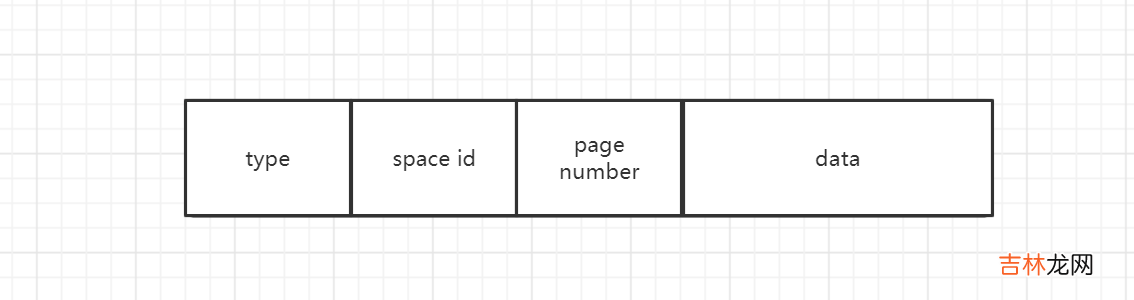
文章插图
- type:redo log日志的类型
- space id:表空间号
- page number:页号
- data:日志内容
理论上说red log只需要记录下insert 语句对页面所有的修改即可 , 但是插入数据到一个页面 , 也伴随着对这个页面的
File Header,Pahe Header等等信息的修改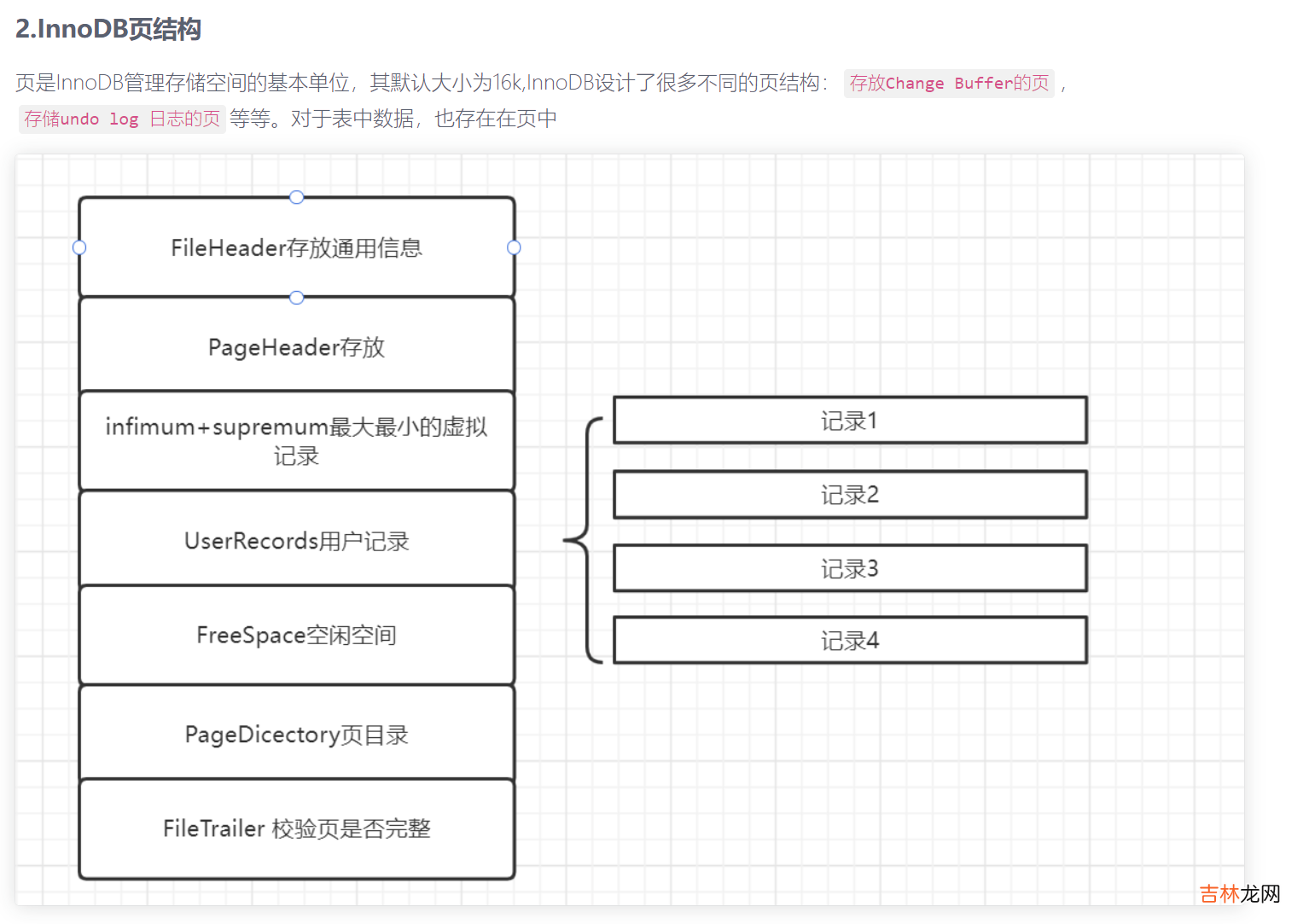
文章插图
可见 , 将一条记录插入到一个页面 , 需要更改的地方很多 , 为此redo log定义了许多不同的日志格式 ,
从物理层面来说:redo log指明了需要在哪一个表空间 , 的哪一个页进行什么修改内容 , 从逻辑层面来说:redo log在mysql崩溃恢复后 , 并不能直接使用这些日志记录的内容 , 而是需要调用一些函数 , 将页面进行恢复
经验总结扩展阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- MySQL的下载、安装、配置
- 我的Vue之旅 09 数据数据库表的存储与获取实现 Mysql + Golang
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
- Mysql InnoDB Buffer Pool
- 「MySQL高级篇」MySQL锁机制 && 事务
- 【MySQL】Navicat15 安装
- 「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
- 「MySQL高级篇」MySQL索引原理,设计原则
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?