在mysql进行崩溃恢复的时候 , 只需要从checkpoint_lsn在日志文件组中对应的偏移量开始 , 扫描到第一个log_block_hdr_data_len值不为512的block为止
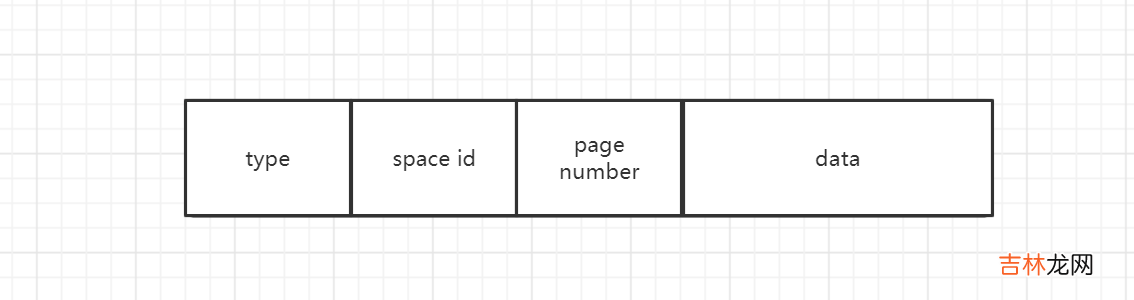
3.如何进行崩溃恢复现在确定了需要恢复的redo log , 那么如何进行恢复昵 , 每一个redo log格式如下
文章插图
3.1化随机io为顺序io其space id记录了表空间号 , page number记录了页号 , 也许这一堆redo log整体上表空间号 , 页号是不具备顺序的 , 如果直接遍历每一个redo log然后对表空间中的页进行恢复 , 是会带来很多随机io的 , 所以innodb使用hash表进行优化 , 将相同表空间号和页号作为key , 这样相同表空间和页的日志就会在同一个hash桶中形成链表中 , 然后遍历每一个hash表的操作 , 一次性将一个页进行恢复 , 化随机io为顺序io
3.2跳过不需要刷新页首先小于最近一次checkpoint_lsn的redo log肯定是不需要进行恢复 , 但是大于的也不一定需要恢复 , 因为可能在做崩溃前的checkpoint的时候 , 后台线程也许将LRU链表和flush链表中的一些脏页刷新到磁盘了 , 那么恢复的时候这些脏页也不需要进行恢复 。那么怎么判断这些不需要恢复的脏页昵?——每一个页面具备file header , 其中有一个属性为file_page_lsn的属性 , 记录了最近一次修改页面时对应的lsn值(即脏页在buffer pool控制块中的newest_modification)如果执行某次checkpoint发现页中的lsn大于最近一次checkpoint的checkpoint_lsn的时候 , 那么说明此页不需要进行更新 。
【Mysql InnoDB Redo log】
经验总结扩展阅读









- MySQL的下载、安装、配置
- 我的Vue之旅 09 数据数据库表的存储与获取实现 Mysql + Golang
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
- Mysql InnoDB Buffer Pool
- 「MySQL高级篇」MySQL锁机制 && 事务
- 【MySQL】Navicat15 安装
- 「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
- 「MySQL高级篇」MySQL索引原理,设计原则
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
- MySQL 全局锁、表级锁、行级锁,你搞清楚了吗?