和以上绝对位置编码的Attention计算对比:
- 语义交互不变
- 位置交互:绝对位置编码内积替换为相对位置编码对应的全局位置偏置, 在表征距离的同时加入了方向信息
- query位置*key语义:因为交互是计算一个query token对全部key token的attention,所以这里的位置编码部分是个常量,作者替换为了trainable的参数u,于是这部分有了更明确的含义就是key对应的全局语义偏置
- query语义*key位置: 替换为query语义 * query和key的相对位置编码,也就是语义和位置交互
Longformer
- paper: Longformer: The Long-Document Transformer
- github:https://github.com/allenai/longformer
- 中文预训练模型:https://github.com/SCHENLIU/longformer-chinese
- Take Away: 滑动窗口稀疏注意力机制
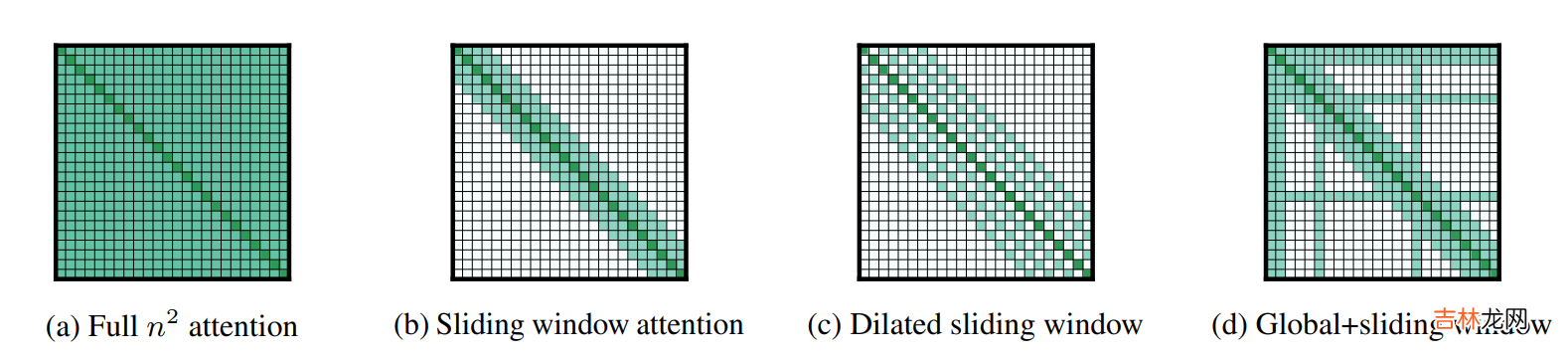
文章插图
Longformer的3点主要创新是
- 滑动窗口attention(图b)
- 空洞滑窗attention(图C)
- 任务导向全局attention(图d)
Longformer的预训练是在Roberta的基础上用长文本进行continue train 。原始Roberta的position embedding只有512维,这里longformer把PE直接复制了8遍,得到4096维度的PE用于初始化,这样在有效保留原始PE局部信息的同时,也和以上512的window-size有了对应 。至于longformer的效果,可以直接看和下面BigBird的对比 。
Bigbird
- paper: Big Bird:Transformers for Longer Sequences
- github: https://github.com/google-research/bigbird
- Take Away: 使用补充固定token计算全局注意力
经验总结扩展阅读
- 孩子评价手册家长怎么填
- 为什么阿里Java开发手册不推荐使用Timestamp
- 青春纪念手册是什么意思?
- iPhone新手使用手册的必备知识 苹果手机如何关机开机
- iPhone手机新手必备操作手册 如何创建新的 Apple ID
- 买美版iPhone手机必看手册 美版无锁苹果手机靠谱吗
- C-RobertKidder是什么
- 沃尔沃完全属于吉利吗
- 保养手册是首保卡吗?
- 摩托车改装手册教你如何改装