文章插图
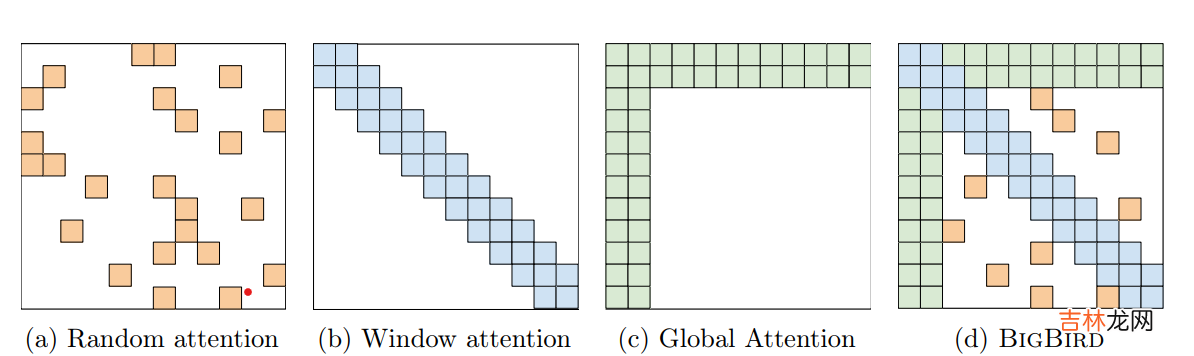
又是一个非常清新脱俗的模型起名~ 大鸟模型和longformer相比增加了随机注意力机制,不过感觉主要的创新是对全局注意力机制进行了改良,提出了固定注意力patten的ETC全局注意力机制 。
- 随机注意力机制
- 全局注意力
整体效果,在QA和长文本摘要任务上上Bigbird基本是新SOTA
Reformer
先来看下原始Transformer的空间复杂度: \(max(b*l* d_{ffn}, b *n_{h} * l^2)*n_{l}\) 。其中b是batch,l是文本长度,\(d_{ffn}\)是Feed Forward层大小,\(n_{h}\)是多头的head size,\(n_l\)是层数 。Reformer引入了三个方案来降低Transformer的计算和内存复杂度
- paper: REFORMER: THE EFFICIENT TRANSFORMER
- github: https://github.com/google/trax/tree/master/trax/models/reformer
- Take Away: LSH搜索序列中的高权重token,做固定长度局部注意力计算
- LSH Attention:近似计算,针对l,只计算注意力中高权重的部分
- 可逆网络:时间换空间,针对\(n_l\),只存储最后一层的参数
- 分块计算:时间换空间,针对\(d_{ffn}\),对FFN层做分块计算
文章插图
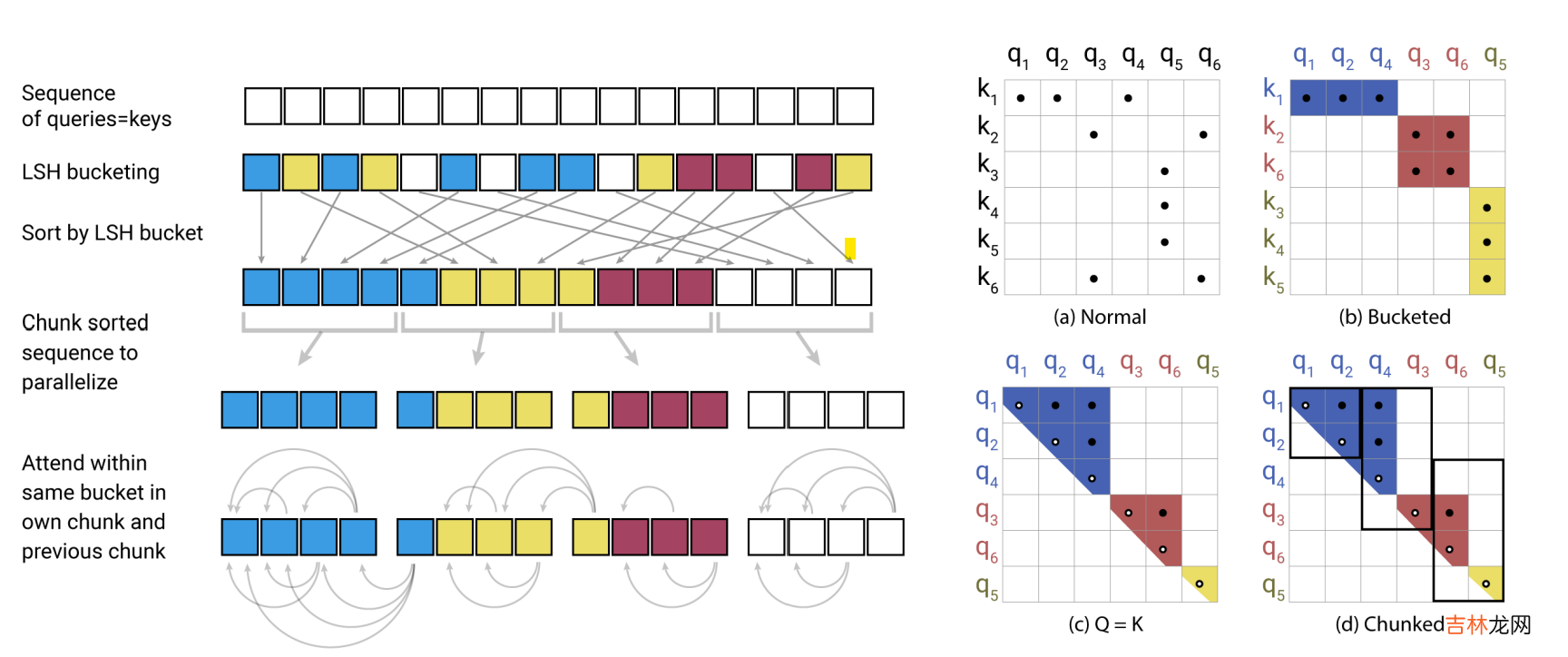
- LSH Attention
LSH使用哈希函数对高位空间的向量x计算哈希函数h(x),\(h(x)\)满足在高维空间中更近的向量有更高的概率落在相同的哈希桶中,反之在高维空间中距离更远的向量有更低的概率会落在相同的哈希桶中 。LSH有很多种算法,这里作者使用的是基于角距离的局部敏感哈希算法 。随机初始化向量R维度是\(d_{model} * bucket/2\),哈希结果为旋转(xR)之后最近的一个正或者负的单位向量\(h(x) = argmax([xR;-xR])\)
使用LSH计算Attention会存在几个问题
- query和key的hashing不同:为了解决这个问题作者把计算注意力之前query和key各自的线性映射统一成了一个,\(k_j=\frac{q_j}{||q_j||}\),这样二者的哈希也会相同,只需要对key进行计算就得到token的哈希分桶 。例如上图(b)长度为6的序列被分成3个桶[1,2,4],[3,6],[5]
经验总结扩展阅读
- 孩子评价手册家长怎么填
- 为什么阿里Java开发手册不推荐使用Timestamp
- 青春纪念手册是什么意思?
- iPhone新手使用手册的必备知识 苹果手机如何关机开机
- iPhone手机新手必备操作手册 如何创建新的 Apple ID
- 买美版iPhone手机必看手册 美版无锁苹果手机靠谱吗
- C-RobertKidder是什么
- 沃尔沃完全属于吉利吗
- 保养手册是首保卡吗?
- 摩托车改装手册教你如何改装













