这一章我们来唠唠如何优化BERT对文本长度的限制 。BERT使用的Transformer结构核心在于注意力机制强大的交互和记忆能力 。不过Attention本身O(n^2)的计算和内存复杂度,也限制了Transformer在长文本中的应用 。
之前对长文档的一些处理方案多是暴力截断,或者分段得到文本表征后再进行融合 。这一章我们看下如何通过优化attention的计算方式,降低内存/计算复杂度,实现长文本建模 。Google出品的Efficient Transformers: A Survey里面对更高效的Transformer魔改进行了分类,这一章我们主要介绍以下5个方向:
- 以Transformer-XL为首的片段递归
- Longformer等通过稀疏注意力,降低内存使用方案
- Performer等通过矩阵分解,降低attention内积计算复杂度的低秩方案
- Reformer等可学习pattern的注意力方案
- Bigbird等固定pattern注意力机制

文章插图
Transformer-xl
为了突破Transformer对固定长度建模的限制,Transformer-xl提出了相对位置编码和片段递归的方案,后续也被XLNET沿用~
- paper: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- github:https://github.com/kimiyoung/transformer-xl
- Take Away: 相对位置编码 + 片段递归机制
文章插图

- 片段递归
具体的Attentenion计算中如下,\(\tau\)是片段,\(n\)是hidden layer,\(\circ\)是向量拼接,\(SG()\)是不进行梯度更新的意思 。于是当前片段Q,K,V是由上个片段的隐藏层和当前片段的隐藏层拼接得到 。每个片段完成计算后会把隐藏层计算结果进行存储,用于下个片段的计算,用空间换时间,既避免了重复计算,又使得新的片段能保留大部分的历史片段信息 。这里的历史片段信息并不一定只使用T-1,理论上在内存允许的情况下可以拼接更多历史片段~
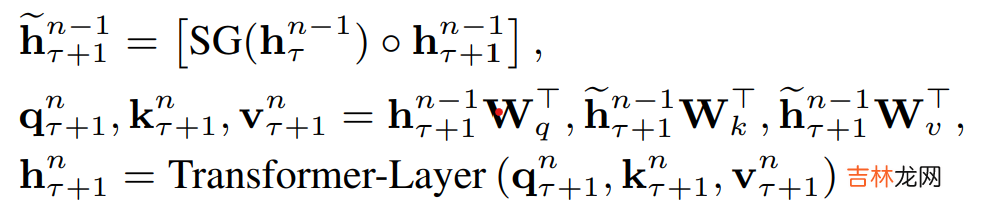
文章插图
- 相对位置编码
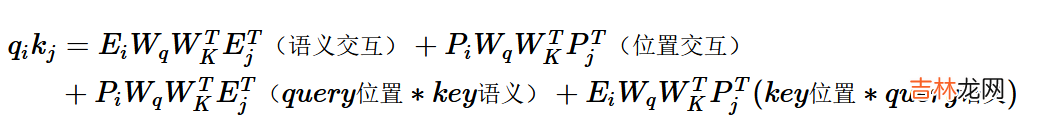
文章插图
绝对位置编码是直接加到词向量上,在Attention计算中进行交互 。把内积展开可以得到如上形式,包括4个部分:Query和Key的纯语义交互,各自的位置信息和语义的交互,以及反映相对距离的位置交互 。
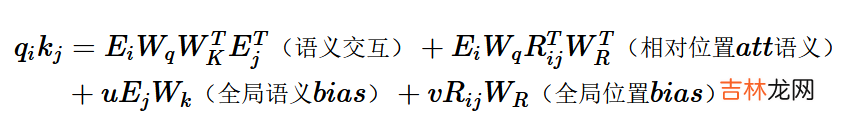
文章插图
Transformer-XL的相对位置编码和以上的展开形式基本一一对应,也使用了三角函数的编码方式,只需要两点调整
- key对应的绝对位置编码\(p_j\)替换为两个token相对位置i-j的相对位置编码\(R_{i,j}\)
- query的位置编码\(P_iW_q\)替换成两个learnable的参数u和v
经验总结扩展阅读
- 孩子评价手册家长怎么填
- 为什么阿里Java开发手册不推荐使用Timestamp
- 青春纪念手册是什么意思?
- iPhone新手使用手册的必备知识 苹果手机如何关机开机
- iPhone手机新手必备操作手册 如何创建新的 Apple ID
- 买美版iPhone手机必看手册 美版无锁苹果手机靠谱吗
- C-RobertKidder是什么
- 沃尔沃完全属于吉利吗
- 保养手册是首保卡吗?
- 摩托车改装手册教你如何改装