实际上 , 由于Hash函数生成的二进制串通常具备均匀的特性 , 所以Hash函数生成的二进制串可以视为抛掷硬币的结果 。
对于一个待进行基数统计的集合(例如一个表中符合条件的字段值) , 为了降低估计的错误率 , 我们分成m组 。某个值归属于哪个组由hash函数生成结果对应的前几位决定 , 剩下的二进制串用于计算当前轮伯努利实验第一次出现正面时抛掷的次数 , 记为p 。
所以算法描述如下:

文章插图
简单来说就是统计每个组最大的p, 然后用现成的公式计算结果即到达预估的结果 。
三、分布式计数核心流程对于Hadoop中的入门案例wordcount , 可以发现如果用Presto SQL表达如下(以tpch数据集customer表name字段为例):
select w, count(1) cnt from (select split(name,'#') words from customer) t1 cross joinUNNEST(t1.words) AS t (w)group by w;可以看出相比大段的代码 , SQL处理对用于来说要简单的多 。无论是哪种表达方式 , 核心点就是分组统计 。
在MapReduce框架核心流程如下:
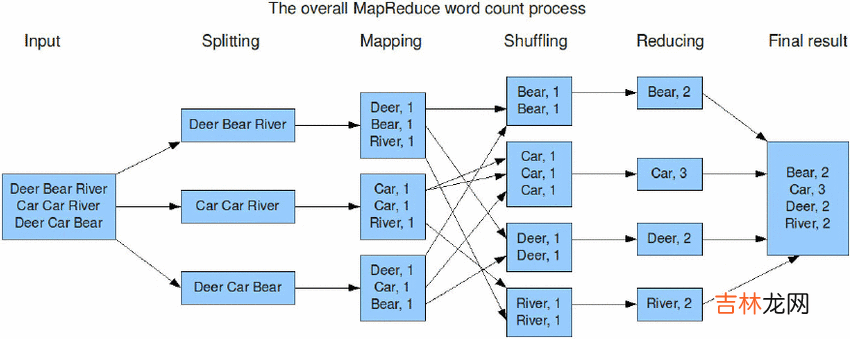
文章插图
那么在Presto , 其执行流程是什么样呢?
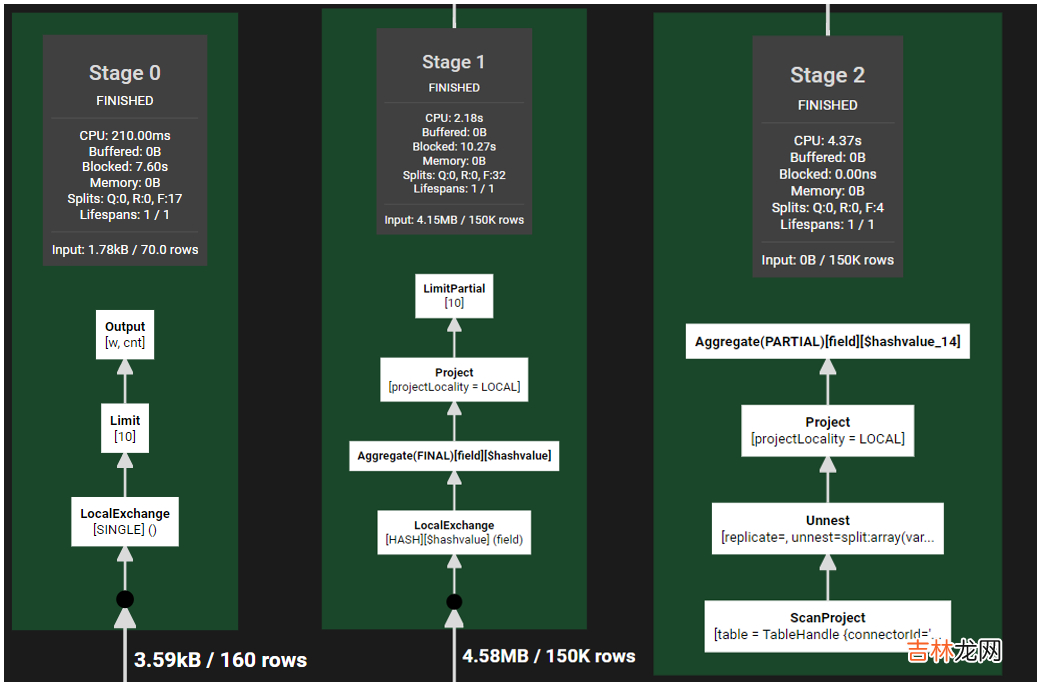
文章插图
从逻辑上 , 都是类似的 。先分组聚合 , 然后汇总聚合 。
四、基数统计在Presto中的落地对于基数统计问题Presto支持两种实现方式 。一种是追求精确的count distinct; 另一种是提供近似统计的approx_distinct 。
count distinct的核心细节
【4 探究Presto SQL引擎-统计计数】以SQL :select count(distinct id) from hive_table 为例 。
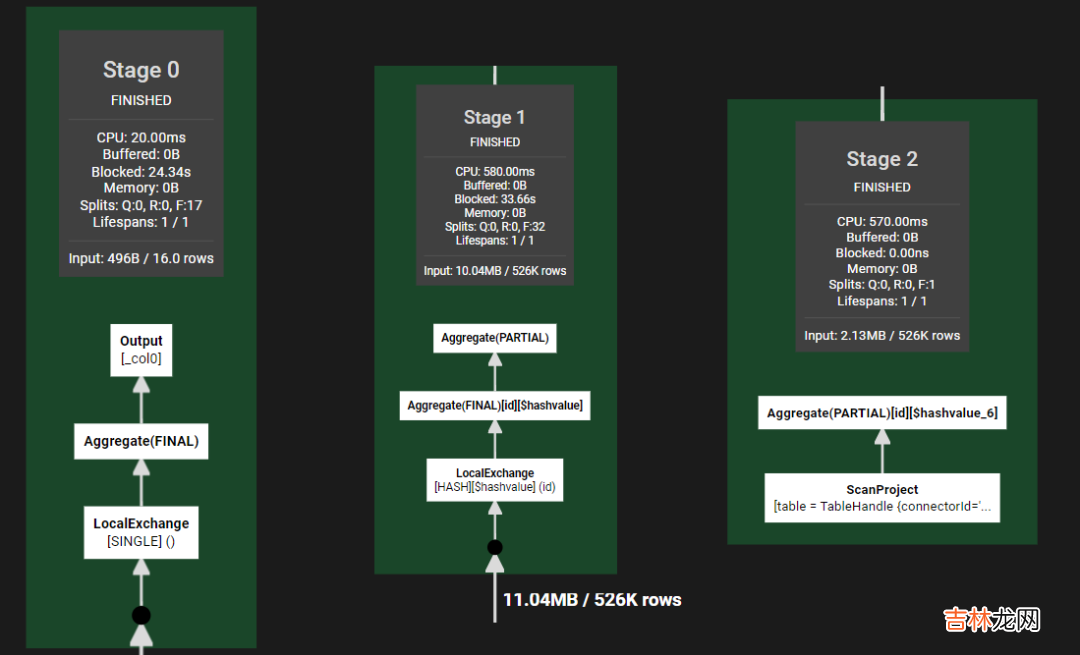
文章插图
即以id为主key, 对数据进行hash分发 , 进行部分聚合 , 最终整体聚合 。依然是map-reduce的思路 , 只不过数据按id进行了分发 。
aprox_distinct的核心细节
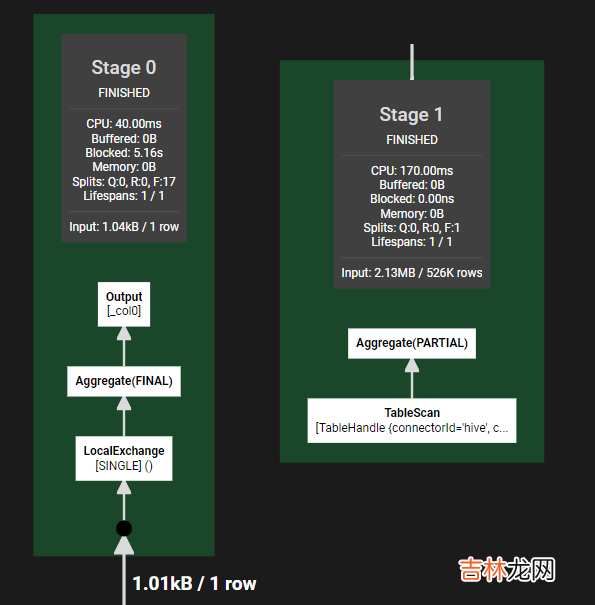
文章插图
这里就免去了基于id的hash分发策略 。所以也减少了一个stage 。至于approx_distinct的内部细节 , 基础框架airlift中 , 封装了HyperLogLog算法的实现 , 采用的函数是MurMurHash3算法 , 生成64位散列值 。前6位用于计算当前散列值所在分组m 。实现过程中还有一个很有意思的细节:基于待统计的数据量 , 实现中同时采用了Linear Count算法和HyperLogLog算法 。
五、业务建议通过上面的分析 , 我们可以发现高基数统计是一个非常消耗内存的操作 , 特别是在分布式系统背景下 , 不仅消耗内存 , 而且涉及大量网络数据传输 。如果分析对应的业务场景 , 可以提供近似值而非精确值 , 那么就能大幅度降低系统消耗和响应时间 , 提升用户体验 。或者在设计产品的时候 , 对于一些场景的计数 , 可以优先提供近似估计 , 如果用户确实需要精确计数 , 那么在管理好用户响应时间预期下 , 再提供查询精确值的接口 。
理解了精确统计和近似统计的细节及各种优缺点 , 处理问题的思路就会更开阔 。例如:在设计存储索引时 , 我们可以优先使用HyperLogLog统计一个字段的基数近似值 , 如果得到的结果不是高基数 , 那么我们可以对字段构建bitmap索引 , 借此提升数据处理的效率 。
经验总结扩展阅读
















- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
- MongoDB - 简单了解
- FlinkSql之TableAPI详解
- 20 基于SqlSugar的开发框架循序渐进介绍-- 在基于UniApp+Vue的移动端实现多条件查询的处理
- 在FreeSQL中实现「触发器」和软删除功能
- Mysql InnoDB Buffer Pool
- Python 多重继承时metaclass conflict问题解决与原理探究
- SQL分层查询
- 「MySQL高级篇」MySQL锁机制 && 事务
- 17 基于SqlSugar的开发框架循序渐进介绍-- 基于CSRedis实现缓存的处理