作者:vivo互联网用户运营开发团队 - Shuai Guangying本篇文章介绍了统计计数的基本原理以及Presto的实现思路 , 精确统计和近似统计的细节及各种优缺点 , 并给出了统计计数在具体业务使用的建议 。
系列文章:
- 探究Presto SQL引擎(1)-巧用Antlr
- 探究Presto SQL引擎(2)-浅析Join
- 探究Presto SQL引擎(3)-代码生成
统计在SQL引擎中可谓最基础、最核心的能力之一 。可能由于它太基础了 , 就像排序一样 , 我们常常会忽视它背后的原理 。通常的计数是非常简单的 , 例如统计文本行数在linux系统上一个wc命令就搞定了 。
除了通常的计数 , 统计不重复元素个数的需求也非常常见 , 这种统计称为基数统计 。对于Presto这种分布式SQL引擎 , 计数的实现原理值得深入研究 , 特别是基数统计 。关于普通计数和基数计数 , 最典型的例子莫过于PV/UV 。
二、基数统计主要算法在SQL语法里面 , 基数统计对应到count(distinct field)或者aprox_distinct() 。通常做精确计数统计需要用到Set这种数据结构 。通过Set不仅可以获得数量信息 , 还能不重不漏地获取每一个元素 。
Set内部有两种实现实现原理:Hash和Tree 。
在海量数据的前提下 , Hash和Tree有一个致命的问题:内存消耗 , 而且随着数据量级的增长 , 内存消耗也是线性增长 。
面对Set内存消耗的问题 , 通常有两种思路:
- 一种是选取其他内存占用更小的数据结构 , 例如bitmap;
- 另一种是放弃精确 , 从数学上寻求近似解 , 典型的算法有Linear Count和HyperLogLog 。
2.1.1 位图向量的构建举个例子 , 假设表user记录如下:
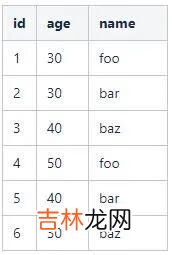
文章插图
这是很典型的一张数据库表 。对于表中的字段 , 如何构建位图索引呢?以age字段为例:
- S1: 确定字段的取值集合空间: {30,40,50} 一共3个选项 。
- S2: 依次为每个选项构建一个长度为6的bit向量 , 得到一个3*6的位图 。3表示字段age的取值基数 , 6表示记录数 。
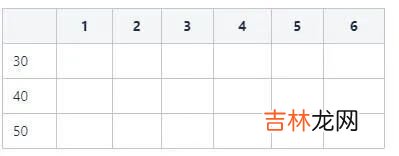
文章插图
- S3: 基于表设置位图相应向量值 。例如:age=30的记录id分别为{1,2,6} , 那么在向量1,2,6位置置为1 , 其他置为0 。得到110001 。
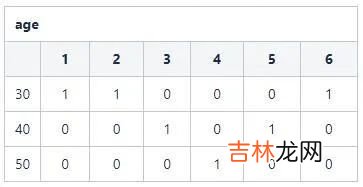
文章插图
同理 , 对于name字段 , 其向量位图为:
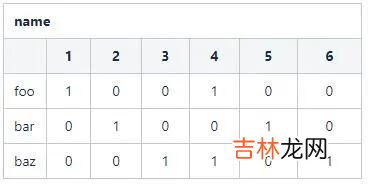
文章插图
可以看出 , 如果对于数据表的一个字段 , 如果记录数为n且字段的取值基数为m , 那么会得到一个m*n的位图 。
经验总结扩展阅读











- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
- MongoDB - 简单了解
- FlinkSql之TableAPI详解
- 20 基于SqlSugar的开发框架循序渐进介绍-- 在基于UniApp+Vue的移动端实现多条件查询的处理
- 在FreeSQL中实现「触发器」和软删除功能
- Mysql InnoDB Buffer Pool
- Python 多重继承时metaclass conflict问题解决与原理探究
- SQL分层查询
- 「MySQL高级篇」MySQL锁机制 && 事务
- 17 基于SqlSugar的开发框架循序渐进介绍-- 基于CSRedis实现缓存的处理